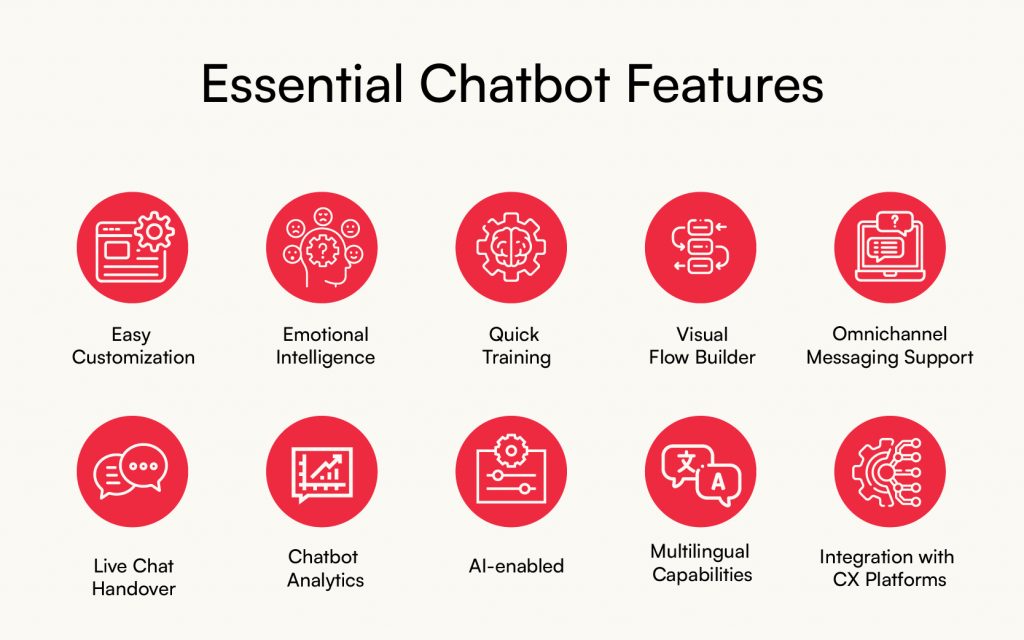
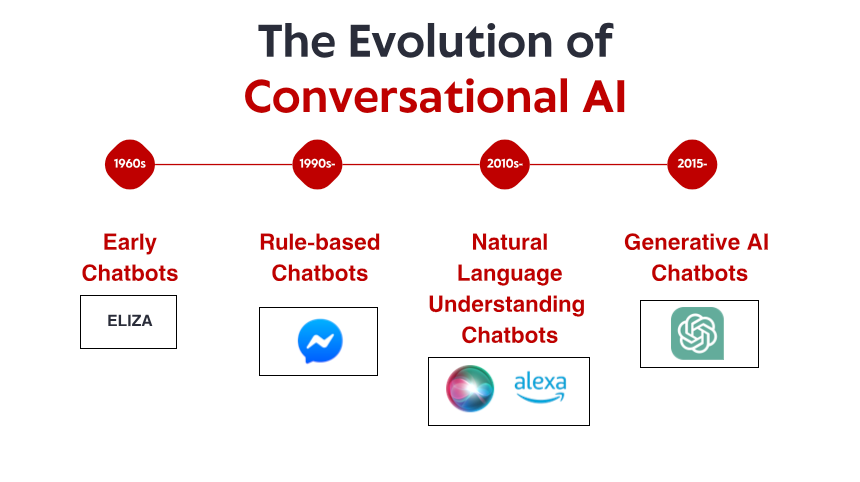
Test AI på DIN hjemmeside på 60 sekunder
Se hvordan vores AI øjeblikkeligt analyserer din hjemmeside og skaber en personlig chatbot - uden registrering. Indtast blot din URL og se den arbejde!
Klar på 60 sekunder
Ingen kodning påkrævet
100% sikker
Privatlivsparadokset for moderne AI-assistenter
Vi har budt dem velkommen i vores hjem, kontorer og lommer. Vi stiller dem spørgsmål i løbet af dagen, beder dem om at spille vores yndlingssange og stoler på, at de styrer vores smarte hjem. AI-drevne samtalegrænseflader er blevet så integreret i dagligdagen, at mange af os interagerer med flere AI-assistenter snesevis af gange hver dag uden en ekstra tanke.
Alligevel ligger der bag disse sømløse interaktioner et komplekst privatlivslandskab, som få brugere fuldt ud forstår. Selve naturen af konversations-AI skaber en grundlæggende spænding: Disse systemer har brug for data - ofte personlige, nogle gange følsomme - for at fungere effektivt, men den samme dataindsamling skaber betydelige privatlivsimplikationer, som ikke kan ignoreres.
Denne spænding repræsenterer, hvad privatlivsforskere kalder "funktionalitet-privatlivsparadokset." For at give personlige, kontekstuelt relevante svar, skal AI-assistenter vide om dig. Dine præferencer, historie, placering og vaner informerer alle om mere nyttige interaktioner. Men hvert stykke information, der indsamles, repræsenterer potentiel eksponering af privatlivets fred, som skal håndteres og beskyttes omhyggeligt.
Indsatsen har aldrig været højere. Efterhånden som samtalegrænseflader bevæger sig ud over simple kommandoer ("Indstil en timer til 10 minutter") til komplekse, kontekstbevidste interaktioner ("Mind mig om at bringe det problem op fra sidste uges e-mail, når jeg mødes med Sarah i morgen"), vokser privatlivsimplikationerne eksponentielt. Disse systemer behandler ikke længere kun isolerede anmodninger, men bygger omfattende brugermodeller, der spænder over flere domæner i vores liv.
For udviklere, virksomheder og brugere, der navigerer i dette landskab, er forståelsen af de unikke privatlivsudfordringer ved samtale-AI det første skridt mod ansvarlig implementering og brug. Lad os udforske dette komplekse terræn og de nye strategier for at balancere kraftfuld funktionalitet med robust privatlivsbeskyttelse.
Alligevel ligger der bag disse sømløse interaktioner et komplekst privatlivslandskab, som få brugere fuldt ud forstår. Selve naturen af konversations-AI skaber en grundlæggende spænding: Disse systemer har brug for data - ofte personlige, nogle gange følsomme - for at fungere effektivt, men den samme dataindsamling skaber betydelige privatlivsimplikationer, som ikke kan ignoreres.
Denne spænding repræsenterer, hvad privatlivsforskere kalder "funktionalitet-privatlivsparadokset." For at give personlige, kontekstuelt relevante svar, skal AI-assistenter vide om dig. Dine præferencer, historie, placering og vaner informerer alle om mere nyttige interaktioner. Men hvert stykke information, der indsamles, repræsenterer potentiel eksponering af privatlivets fred, som skal håndteres og beskyttes omhyggeligt.
Indsatsen har aldrig været højere. Efterhånden som samtalegrænseflader bevæger sig ud over simple kommandoer ("Indstil en timer til 10 minutter") til komplekse, kontekstbevidste interaktioner ("Mind mig om at bringe det problem op fra sidste uges e-mail, når jeg mødes med Sarah i morgen"), vokser privatlivsimplikationerne eksponentielt. Disse systemer behandler ikke længere kun isolerede anmodninger, men bygger omfattende brugermodeller, der spænder over flere domæner i vores liv.
For udviklere, virksomheder og brugere, der navigerer i dette landskab, er forståelsen af de unikke privatlivsudfordringer ved samtale-AI det første skridt mod ansvarlig implementering og brug. Lad os udforske dette komplekse terræn og de nye strategier for at balancere kraftfuld funktionalitet med robust privatlivsbeskyttelse.
Forstå, hvad der virkelig sker med dine stemmedata
Når du interagerer med et konversations-AI-system, hvad sker der så med dine data? Rejsen er mere kompleks – og ofte mere omfattende – end mange brugere er klar over.
Processen begynder typisk med datafangst. Stemmebaserede systemer konverterer lyd til digitale signaler, mens tekstbaserede interfaces fanger indtastede input. Disse rådata gennemgår derefter flere behandlingsstadier, der kan omfatte:
Tale-til-tekst konvertering til stemmeinput
Naturlig sprogbehandling for at bestemme hensigten
Kontekstanalyse, der kan inkorporere tidligere interaktioner
Responsgenerering baseret på trænede AI-modeller
Yderligere behandling for personalisering
Lagring af interaktioner til systemforbedring
Hver fase præsenterer særskilte privatlivsovervejelser. Hvor foregår for eksempel tale-til-tekst-konverteringen - på din enhed eller på fjernservere? Gemmes optagelser af din stemme, og i givet fald hvor længe? Hvem kan have adgang til disse optagelser? Lytter systemet konstant, eller kun efter et wake word?
Store udbydere har forskellige tilgange til disse spørgsmål. Nogle behandler alle data i skyen, mens andre udfører indledende behandling på enheden for at begrænse datatransmission. Lagringspolitikker varierer meget, fra ubestemt opbevaring til automatisk sletning efter specificerede perioder. Adgangskontrol spænder fra strenge begrænsninger til autoriseret brug af menneskelige anmeldere til kvalitetsforbedring.
Virkeligheden er, at selv når virksomheder har stærke privatlivspolitikker, gør den iboende kompleksitet af disse systemer det vanskeligt for brugerne at bevare klar synlighed i præcis, hvordan deres data bliver brugt. Nylige afsløringer om menneskelige anmeldere, der lyttede til stemmeassistentoptagelser, overraskede mange brugere, der antog, at deres interaktioner forblev helt private eller kun blev behandlet af automatiserede systemer.
Tilføjelse til denne kompleksitet er den distribuerede karakter af moderne AI-assistenter. Når du spørger din smarte højttaler om restauranter i nærheden, kan den forespørgsel interagere med flere systemer – assistentens kerne-AI, korttjenester, restaurantdatabaser, anmeldelsesplatforme – hver med sin egen datapraksis og privatlivsimplikationer.
For at brugerne kan træffe informerede valg, er større gennemsigtighed omkring disse processer afgørende. Nogle udbydere har gjort fremskridt i denne retning, og tilbyder klarere forklaringer af datapraksis, mere detaljerede styringer af privatlivets fred og muligheder for at gennemgå og slette historiske data. Der er dog stadig betydelige huller i at hjælpe brugerne med virkelig at forstå privatlivsimplikationerne af deres daglige AI-interaktioner.
Processen begynder typisk med datafangst. Stemmebaserede systemer konverterer lyd til digitale signaler, mens tekstbaserede interfaces fanger indtastede input. Disse rådata gennemgår derefter flere behandlingsstadier, der kan omfatte:
Tale-til-tekst konvertering til stemmeinput
Naturlig sprogbehandling for at bestemme hensigten
Kontekstanalyse, der kan inkorporere tidligere interaktioner
Responsgenerering baseret på trænede AI-modeller
Yderligere behandling for personalisering
Lagring af interaktioner til systemforbedring
Hver fase præsenterer særskilte privatlivsovervejelser. Hvor foregår for eksempel tale-til-tekst-konverteringen - på din enhed eller på fjernservere? Gemmes optagelser af din stemme, og i givet fald hvor længe? Hvem kan have adgang til disse optagelser? Lytter systemet konstant, eller kun efter et wake word?
Store udbydere har forskellige tilgange til disse spørgsmål. Nogle behandler alle data i skyen, mens andre udfører indledende behandling på enheden for at begrænse datatransmission. Lagringspolitikker varierer meget, fra ubestemt opbevaring til automatisk sletning efter specificerede perioder. Adgangskontrol spænder fra strenge begrænsninger til autoriseret brug af menneskelige anmeldere til kvalitetsforbedring.
Virkeligheden er, at selv når virksomheder har stærke privatlivspolitikker, gør den iboende kompleksitet af disse systemer det vanskeligt for brugerne at bevare klar synlighed i præcis, hvordan deres data bliver brugt. Nylige afsløringer om menneskelige anmeldere, der lyttede til stemmeassistentoptagelser, overraskede mange brugere, der antog, at deres interaktioner forblev helt private eller kun blev behandlet af automatiserede systemer.
Tilføjelse til denne kompleksitet er den distribuerede karakter af moderne AI-assistenter. Når du spørger din smarte højttaler om restauranter i nærheden, kan den forespørgsel interagere med flere systemer – assistentens kerne-AI, korttjenester, restaurantdatabaser, anmeldelsesplatforme – hver med sin egen datapraksis og privatlivsimplikationer.
For at brugerne kan træffe informerede valg, er større gennemsigtighed omkring disse processer afgørende. Nogle udbydere har gjort fremskridt i denne retning, og tilbyder klarere forklaringer af datapraksis, mere detaljerede styringer af privatlivets fred og muligheder for at gennemgå og slette historiske data. Der er dog stadig betydelige huller i at hjælpe brugerne med virkelig at forstå privatlivsimplikationerne af deres daglige AI-interaktioner.
Det regulatoriske landskab: Udvikling, men inkonsekvent
Conversational AI opererer i et regulatorisk miljø, der på samme tid udvikler sig hurtigt og frustrerende fragmenteret. Forskellige regioner har etableret forskellige tilgange til databeskyttelse, der direkte påvirker, hvordan samtalegrænseflader kan designes og implementeres.
Den Europæiske Unions generelle databeskyttelsesforordning (GDPR) repræsenterer en af de mest omfattende rammer, der etablerer principper, der væsentligt påvirker samtale AI:
Kravet om specifikt, informeret samtykke før behandling af personoplysninger
Dataminimeringsprincipper, der begrænser indsamlingen til det nødvendige
Formålsbegrænsning, der begrænser brugen af data ud over angivne hensigter
Retten til at få adgang til personoplysninger, som virksomheder har
Retten til at blive glemt (datasletning efter anmodning)
Krav til dataportabilitet mellem tjenester
Disse krav giver særlige udfordringer for konversations-AI, som ofte er afhængig af bred dataindsamling og kan kæmpe med klare formålsbegrænsninger, når systemer er designet til at håndtere varierede og uforudsigelige anmodninger.
I USA er reguleringen af privatlivets fred stadig mere fragmenteret, idet California Consumer Privacy Act (CCPA) og dens efterfølger California Privacy Rights Act (CPRA) etablerer den stærkeste beskyttelse på statsniveau. Disse regler giver indbyggere i Californien rettigheder svarende til dem under GDPR, herunder adgang til personlige oplysninger og retten til at slette data. Andre stater har fulgt efter med deres egen lovgivning og skabt et kludetæppe af krav over hele landet.
Specialiserede regler tilføjer yderligere kompleksitet. I sundhedsmæssige sammenhænge stiller HIPAA-reglerne i USA strenge krav til håndtering af medicinsk information. For tjenester rettet mod børn etablerer COPPA yderligere beskyttelse, der begrænser dataindsamling og brug.
Den globale karakter af de fleste samtale-AI-tjenester betyder, at virksomheder typisk skal designe efter de strengeste gældende regler, mens de administrerer overholdelse på tværs af flere jurisdiktioner. Dette komplekse landskab skaber udfordringer både for etablerede virksomheder, der navigerer efter forskellige krav, og for startups med begrænsede juridiske ressourcer.
For brugere betyder det inkonsekvente lovgivningsmæssige miljø, at beskyttelsen af privatlivets fred kan variere betydeligt afhængigt af, hvor de bor. Dem i regioner med stærke databeskyttelseslove har generelt flere rettigheder med hensyn til deres samtale-AI-data, mens andre kan have færre juridiske beskyttelser.
Det regulatoriske landskab fortsætter med at udvikle sig, med ny lovgivning under udvikling i mange regioner, der specifikt omhandler AI-styring. Disse nye rammer kan give mere skræddersyede tilgange til samtale-AIs unikke privatlivsudfordringer, hvilket potentielt kan etablere klarere standarder for samtykke, gennemsigtighed og datastyring i disse stadig vigtigere systemer.
Den Europæiske Unions generelle databeskyttelsesforordning (GDPR) repræsenterer en af de mest omfattende rammer, der etablerer principper, der væsentligt påvirker samtale AI:
Kravet om specifikt, informeret samtykke før behandling af personoplysninger
Dataminimeringsprincipper, der begrænser indsamlingen til det nødvendige
Formålsbegrænsning, der begrænser brugen af data ud over angivne hensigter
Retten til at få adgang til personoplysninger, som virksomheder har
Retten til at blive glemt (datasletning efter anmodning)
Krav til dataportabilitet mellem tjenester
Disse krav giver særlige udfordringer for konversations-AI, som ofte er afhængig af bred dataindsamling og kan kæmpe med klare formålsbegrænsninger, når systemer er designet til at håndtere varierede og uforudsigelige anmodninger.
I USA er reguleringen af privatlivets fred stadig mere fragmenteret, idet California Consumer Privacy Act (CCPA) og dens efterfølger California Privacy Rights Act (CPRA) etablerer den stærkeste beskyttelse på statsniveau. Disse regler giver indbyggere i Californien rettigheder svarende til dem under GDPR, herunder adgang til personlige oplysninger og retten til at slette data. Andre stater har fulgt efter med deres egen lovgivning og skabt et kludetæppe af krav over hele landet.
Specialiserede regler tilføjer yderligere kompleksitet. I sundhedsmæssige sammenhænge stiller HIPAA-reglerne i USA strenge krav til håndtering af medicinsk information. For tjenester rettet mod børn etablerer COPPA yderligere beskyttelse, der begrænser dataindsamling og brug.
Den globale karakter af de fleste samtale-AI-tjenester betyder, at virksomheder typisk skal designe efter de strengeste gældende regler, mens de administrerer overholdelse på tværs af flere jurisdiktioner. Dette komplekse landskab skaber udfordringer både for etablerede virksomheder, der navigerer efter forskellige krav, og for startups med begrænsede juridiske ressourcer.
For brugere betyder det inkonsekvente lovgivningsmæssige miljø, at beskyttelsen af privatlivets fred kan variere betydeligt afhængigt af, hvor de bor. Dem i regioner med stærke databeskyttelseslove har generelt flere rettigheder med hensyn til deres samtale-AI-data, mens andre kan have færre juridiske beskyttelser.
Det regulatoriske landskab fortsætter med at udvikle sig, med ny lovgivning under udvikling i mange regioner, der specifikt omhandler AI-styring. Disse nye rammer kan give mere skræddersyede tilgange til samtale-AIs unikke privatlivsudfordringer, hvilket potentielt kan etablere klarere standarder for samtykke, gennemsigtighed og datastyring i disse stadig vigtigere systemer.
De tekniske udfordringer ved privatlivsbevarende konversations-AI
Opbygning af konversations-AI, der respekterer privatlivets fred og samtidig opretholde høj funktionalitet, giver betydelige tekniske udfordringer. Disse systemer har traditionelt været afhængige af centraliseret cloud-behandling og omfattende dataindsamling – tilgange, der kan være i konflikt med bedste praksis for privatliv.
Adskillige vigtige tekniske udfordringer står i skæringspunktet mellem samtale-AI og privatliv:
On-Device Processing vs. Cloud Computing
Flytning af behandling fra skyen til enheden (edge computing) kan forbedre privatlivets fred betydeligt ved at holde følsomme data lokale. Denne tilgang står imidlertid over for væsentlige begrænsninger:
Mobil- og hjemmeenheder har begrænsede beregningsressourcer sammenlignet med cloud-infrastruktur
Større AI-modeller passer muligvis ikke på forbrugerenheder
Modeller på enheden kan levere svar af lavere kvalitet uden adgang til centraliseret læring
Hyppige modelopdateringer kan forbruge betydelig båndbredde og lagerplads
På trods af disse udfordringer gør fremskridt inden for modelkomprimering og specialiseret AI-hardware behandling på enheden stadig mere levedygtig. Nogle systemer bruger nu hybride tilgange, der udfører indledende behandling lokalt og sender kun nødvendige data til skyen.
Maskinlæring, der bevarer privatlivets fred
Traditionelle maskinlæringstilgange har været centreret omkring centraliseret dataindsamling, men privatlivsfokuserede alternativer dukker op:
Fødereret læring gør det muligt for modeller at blive trænet på tværs af mange enheder, mens personlige data holdes lokale. Kun modelopdateringer (ikke brugerdata) deles med centrale servere, hvilket beskytter den enkeltes privatliv, mens det stadig muliggør systemforbedring.
Differentiel privatliv introducerer beregnet støj i datasæt eller forespørgsler for at forhindre identifikation af individer, samtidig med at statistisk validitet for træning og analyse bevares.
Sikker multi-party beregning muliggør analyse på tværs af flere datakilder, uden at nogen part behøver at afsløre deres rå data til andre.
Disse teknikker viser lovende, men kommer med afvejninger i beregningseffektivitet, implementeringskompleksitet og nogle gange reduceret nøjagtighed sammenlignet med traditionelle tilgange.
Dataminimeringsstrategier
Privatlivscentreret design kræver kun at indsamle de data, der er nødvendige for den tilsigtede funktionalitet, men at definere "nødvendigt" for fleksible samtalesystemer giver vanskeligheder:
Hvordan kan systemer på forhånd bestemme, hvilken kontekst der kan være nødvendig for fremtidige interaktioner?
Hvilke grundlæggende oplysninger er nødvendige for at give personlige, men privatlivsrespekterende oplevelser?
Hvordan kan systemer balancere umiddelbare funktionalitetsbehov mod potentiel fremtidig nytte?
Nogle tilgange fokuserer på tidsbegrænset dataopbevaring, og gemmer kun interaktionshistorik i definerede perioder, der er relevante for forventede brugsmønstre. Andre lægger vægt på brugerkontrol, hvilket giver enkeltpersoner mulighed for at specificere, hvilke historiske data der skal vedligeholdes eller glemmes.
Anonymiseringsbegrænsninger
Traditionelle anonymiseringsteknikker viser sig ofte at være utilstrækkelige til samtaledata, som indeholder rig kontekstuel information, der kan lette genidentifikation:
Talemønstre og ordvalg kan være meget identificerende
Spørgsmål om personlige forhold kan afsløre identificerbare detaljer, selv når direkte identificerende oplysninger fjernes
Den kumulative effekt af flere interaktioner kan skabe identificerbare profiler selv fra tilsyneladende anonyme individuelle udvekslinger
Forskning i avancerede anonymiseringsteknikker, der er specielt designet til samtaleindhold, fortsætter, men perfekt anonymisering, samtidig med at brugen bevares, forbliver et uhåndgribeligt mål.
Disse tekniske udfordringer fremhæver, hvorfor privatlivsbevarende samtale-AI kræver fundamentalt nye tilgange frem for blot at anvende traditionelle privatlivsteknikker til eksisterende AI-arkitekturer. Fremskridt kræver dybt samarbejde mellem AI-forskere, privatlivseksperter og systemarkitekter for at udvikle tilgange, der respekterer privacy by design snarere end som en eftertanke.
Adskillige vigtige tekniske udfordringer står i skæringspunktet mellem samtale-AI og privatliv:
On-Device Processing vs. Cloud Computing
Flytning af behandling fra skyen til enheden (edge computing) kan forbedre privatlivets fred betydeligt ved at holde følsomme data lokale. Denne tilgang står imidlertid over for væsentlige begrænsninger:
Mobil- og hjemmeenheder har begrænsede beregningsressourcer sammenlignet med cloud-infrastruktur
Større AI-modeller passer muligvis ikke på forbrugerenheder
Modeller på enheden kan levere svar af lavere kvalitet uden adgang til centraliseret læring
Hyppige modelopdateringer kan forbruge betydelig båndbredde og lagerplads
På trods af disse udfordringer gør fremskridt inden for modelkomprimering og specialiseret AI-hardware behandling på enheden stadig mere levedygtig. Nogle systemer bruger nu hybride tilgange, der udfører indledende behandling lokalt og sender kun nødvendige data til skyen.
Maskinlæring, der bevarer privatlivets fred
Traditionelle maskinlæringstilgange har været centreret omkring centraliseret dataindsamling, men privatlivsfokuserede alternativer dukker op:
Fødereret læring gør det muligt for modeller at blive trænet på tværs af mange enheder, mens personlige data holdes lokale. Kun modelopdateringer (ikke brugerdata) deles med centrale servere, hvilket beskytter den enkeltes privatliv, mens det stadig muliggør systemforbedring.
Differentiel privatliv introducerer beregnet støj i datasæt eller forespørgsler for at forhindre identifikation af individer, samtidig med at statistisk validitet for træning og analyse bevares.
Sikker multi-party beregning muliggør analyse på tværs af flere datakilder, uden at nogen part behøver at afsløre deres rå data til andre.
Disse teknikker viser lovende, men kommer med afvejninger i beregningseffektivitet, implementeringskompleksitet og nogle gange reduceret nøjagtighed sammenlignet med traditionelle tilgange.
Dataminimeringsstrategier
Privatlivscentreret design kræver kun at indsamle de data, der er nødvendige for den tilsigtede funktionalitet, men at definere "nødvendigt" for fleksible samtalesystemer giver vanskeligheder:
Hvordan kan systemer på forhånd bestemme, hvilken kontekst der kan være nødvendig for fremtidige interaktioner?
Hvilke grundlæggende oplysninger er nødvendige for at give personlige, men privatlivsrespekterende oplevelser?
Hvordan kan systemer balancere umiddelbare funktionalitetsbehov mod potentiel fremtidig nytte?
Nogle tilgange fokuserer på tidsbegrænset dataopbevaring, og gemmer kun interaktionshistorik i definerede perioder, der er relevante for forventede brugsmønstre. Andre lægger vægt på brugerkontrol, hvilket giver enkeltpersoner mulighed for at specificere, hvilke historiske data der skal vedligeholdes eller glemmes.
Anonymiseringsbegrænsninger
Traditionelle anonymiseringsteknikker viser sig ofte at være utilstrækkelige til samtaledata, som indeholder rig kontekstuel information, der kan lette genidentifikation:
Talemønstre og ordvalg kan være meget identificerende
Spørgsmål om personlige forhold kan afsløre identificerbare detaljer, selv når direkte identificerende oplysninger fjernes
Den kumulative effekt af flere interaktioner kan skabe identificerbare profiler selv fra tilsyneladende anonyme individuelle udvekslinger
Forskning i avancerede anonymiseringsteknikker, der er specielt designet til samtaleindhold, fortsætter, men perfekt anonymisering, samtidig med at brugen bevares, forbliver et uhåndgribeligt mål.
Disse tekniske udfordringer fremhæver, hvorfor privatlivsbevarende samtale-AI kræver fundamentalt nye tilgange frem for blot at anvende traditionelle privatlivsteknikker til eksisterende AI-arkitekturer. Fremskridt kræver dybt samarbejde mellem AI-forskere, privatlivseksperter og systemarkitekter for at udvikle tilgange, der respekterer privacy by design snarere end som en eftertanke.
Gennemsigtighed og samtykke: Nytænkning af brugerkontrol
AI-assistenternes samtalekarakter skaber unikke udfordringer for traditionelle modeller for gennemsigtighed og samtykke. Standardtilgange – såsom lange privatlivspolitikker eller engangsanmodninger om samtykke – viser sig at være særligt utilstrækkelige i denne sammenhæng.
Flere faktorer komplicerer gennemsigtighed og samtykke til samtalegrænseflader:
Den afslappede, talebaserede interaktionsmodel egner sig ikke til detaljerede privatlivsforklaringer
Brugere skelner ofte ikke mellem forskellige funktionelle domæner, der kan have forskellige privatlivsimplikationer
Det igangværende forhold til samtale-AI skaber flere potentielle samtykke-øjeblikke
Kontekstbevidste systemer kan indsamle oplysninger, som brugerne ikke udtrykkeligt havde til hensigt at dele
Tredjepartsintegrationer skaber komplekse datastrømme, som er svære at kommunikere klart
Progressive virksomheder udforsker nye tilgange, der er bedre egnet til disse udfordringer:
Lagdelt afsløring
I stedet for at overvælde brugere med omfattende privatlivsoplysninger på én gang, giver lagdelt offentliggørelse information i fordøjelige segmenter på relevante tidspunkter:
Den indledende opsætning inkluderer grundlæggende valg af privatliv
Funktionsspecifikke privatlivsimplikationer forklares, når nye funktioner bruges
Periodiske "check-ins" til privatlivets fred gennemgår dataindsamling og brug
Privatlivsoplysninger er tilgængelige efter behov via specifikke stemmekommandoer
Denne tilgang anerkender, at forståelsen af privatlivets fred udvikler sig over tid gennem gentagne interaktioner snarere end fra en enkelt afsløringshændelse.
Kontekstuelt samtykke
Ud over binære til-/fravalgsmodeller søger kontekstuelt samtykke tilladelse på meningsfulde beslutningspunkter i brugerrejsen:
Når en ny type persondata ville blive indsamlet
Før du aktiverer funktioner med betydelige privatlivsimplikationer
Når du skifter fra lokal til cloud-behandling
Før du deler data med tredjepartstjenester
Ved ændring af, hvordan tidligere indsamlede data vil blive brugt
Kritisk set giver kontekstuelt samtykke tilstrækkelig information til informerede beslutninger uden at overvælde brugerne, hvilket forklarer både fordelene og privatlivets fredsimplikationer af hvert valg.
Interaktiv privatlivskontrol
Voice-first-grænseflader kræver stemmetilgængelige privatlivskontroller. Førende systemer udvikler naturlige sproggrænseflader til privatlivsstyring:
"Hvilke oplysninger gemmer du om mig?"
"Slet min indkøbshistorik fra sidste uge"
"Stop med at gemme mine stemmeoptagelser"
"Hvem har adgang til mine spørgsmål om sundhedsemner?"
Disse konversationsstyringer til privatlivets fred gør beskyttelse mere tilgængelig end nedgravede indstillingsmenuer, selvom de præsenterer deres egne designudfordringer med at bekræfte brugerens identitet og hensigt.
Privatlivspersonas og præferencelæring
Nogle systemer udforsker privatlivs-"personas" eller profiler, der samler relaterede privatlivsvalg for at forenkle beslutningstagningen. Andre bruger maskinlæring til at forstå individuelle privatlivspræferencer over tid, og foreslår passende indstillinger baseret på tidligere valg, mens de stadig bevarer eksplicit kontrol.
For virksomheder og udviklere kræver design af effektive gennemsigtigheds- og samtykkemekanismer, at man anerkender, at brugere har forskellige privatlivspræferencer og læsefærdighedsniveauer. De mest succesrige tilgange tilgodeser denne mangfoldighed ved at give flere veje til forståelse og kontrol frem for ensartede løsninger.
Efterhånden som konversations-AI bliver dybere integreret i det daglige liv, er det stadig en vedvarende designudfordring at skabe grænseflader, der effektivt kommunikerer privatlivsimplikationer uden at forstyrre naturlig interaktion – men en væsentlig udfordring for at opbygge troværdige systemer.
Flere faktorer komplicerer gennemsigtighed og samtykke til samtalegrænseflader:
Den afslappede, talebaserede interaktionsmodel egner sig ikke til detaljerede privatlivsforklaringer
Brugere skelner ofte ikke mellem forskellige funktionelle domæner, der kan have forskellige privatlivsimplikationer
Det igangværende forhold til samtale-AI skaber flere potentielle samtykke-øjeblikke
Kontekstbevidste systemer kan indsamle oplysninger, som brugerne ikke udtrykkeligt havde til hensigt at dele
Tredjepartsintegrationer skaber komplekse datastrømme, som er svære at kommunikere klart
Progressive virksomheder udforsker nye tilgange, der er bedre egnet til disse udfordringer:
Lagdelt afsløring
I stedet for at overvælde brugere med omfattende privatlivsoplysninger på én gang, giver lagdelt offentliggørelse information i fordøjelige segmenter på relevante tidspunkter:
Den indledende opsætning inkluderer grundlæggende valg af privatliv
Funktionsspecifikke privatlivsimplikationer forklares, når nye funktioner bruges
Periodiske "check-ins" til privatlivets fred gennemgår dataindsamling og brug
Privatlivsoplysninger er tilgængelige efter behov via specifikke stemmekommandoer
Denne tilgang anerkender, at forståelsen af privatlivets fred udvikler sig over tid gennem gentagne interaktioner snarere end fra en enkelt afsløringshændelse.
Kontekstuelt samtykke
Ud over binære til-/fravalgsmodeller søger kontekstuelt samtykke tilladelse på meningsfulde beslutningspunkter i brugerrejsen:
Når en ny type persondata ville blive indsamlet
Før du aktiverer funktioner med betydelige privatlivsimplikationer
Når du skifter fra lokal til cloud-behandling
Før du deler data med tredjepartstjenester
Ved ændring af, hvordan tidligere indsamlede data vil blive brugt
Kritisk set giver kontekstuelt samtykke tilstrækkelig information til informerede beslutninger uden at overvælde brugerne, hvilket forklarer både fordelene og privatlivets fredsimplikationer af hvert valg.
Interaktiv privatlivskontrol
Voice-first-grænseflader kræver stemmetilgængelige privatlivskontroller. Førende systemer udvikler naturlige sproggrænseflader til privatlivsstyring:
"Hvilke oplysninger gemmer du om mig?"
"Slet min indkøbshistorik fra sidste uge"
"Stop med at gemme mine stemmeoptagelser"
"Hvem har adgang til mine spørgsmål om sundhedsemner?"
Disse konversationsstyringer til privatlivets fred gør beskyttelse mere tilgængelig end nedgravede indstillingsmenuer, selvom de præsenterer deres egne designudfordringer med at bekræfte brugerens identitet og hensigt.
Privatlivspersonas og præferencelæring
Nogle systemer udforsker privatlivs-"personas" eller profiler, der samler relaterede privatlivsvalg for at forenkle beslutningstagningen. Andre bruger maskinlæring til at forstå individuelle privatlivspræferencer over tid, og foreslår passende indstillinger baseret på tidligere valg, mens de stadig bevarer eksplicit kontrol.
For virksomheder og udviklere kræver design af effektive gennemsigtigheds- og samtykkemekanismer, at man anerkender, at brugere har forskellige privatlivspræferencer og læsefærdighedsniveauer. De mest succesrige tilgange tilgodeser denne mangfoldighed ved at give flere veje til forståelse og kontrol frem for ensartede løsninger.
Efterhånden som konversations-AI bliver dybere integreret i det daglige liv, er det stadig en vedvarende designudfordring at skabe grænseflader, der effektivt kommunikerer privatlivsimplikationer uden at forstyrre naturlig interaktion – men en væsentlig udfordring for at opbygge troværdige systemer.
Test AI på DIN hjemmeside på 60 sekunder
Se hvordan vores AI øjeblikkeligt analyserer din hjemmeside og skaber en personlig chatbot - uden registrering. Indtast blot din URL og se den arbejde!
Klar på 60 sekunder
Ingen kodning påkrævet
100% sikker
Særlige hensyn til udsatte befolkningsgrupper
Conversational AI rejser øgede bekymringer om privatlivets fred for sårbare befolkningsgrupper, hvis specifikke behov muligvis ikke imødekommes tilstrækkeligt af generelle privatlivstilgange. Disse grupper omfatter børn, ældre voksne, personer med kognitive handicap og dem med begrænset teknologisk viden.
Børn og privatliv
Børn repræsenterer en befolkning af særlig bekymring, da de måske ikke forstår konsekvenserne af privatlivets fred, men i stigende grad interagerer med samtalegrænseflader:
Mange børn mangler udviklingsevnen til at træffe informerede privatlivsbeslutninger
Børn kan dele information mere frit i samtale uden at forstå potentielle konsekvenser
Unge brugere skelner muligvis ikke mellem at tale med en AI og en betroet menneskelig fortrolig
Data indsamlet i barndommen kan potentielt følge individer i årtier
Regulatoriske rammer som COPPA i USA og GDPR's specifikke bestemmelser for børn etablerer basisbeskyttelse, men implementeringsudfordringer er stadig. Stemmegenkendelsesteknologi kan have svært ved at identificere børnebrugere pålideligt, hvilket komplicerer alderssvarende privatlivsforanstaltninger. Systemer, der primært er designet til voksne, forklarer muligvis ikke begreber om beskyttelse af personlige oplysninger tilstrækkeligt på et sprog, der er tilgængeligt for børn.
Udviklere, der skaber børnefokuseret samtale-AI eller funktioner, skal overveje specialiserede tilgange, herunder:
Standardindstillinger for høj privatliv med forældrekontrol til justeringer
Alderssvarende forklaringer af dataindsamling ved hjælp af konkrete eksempler
Begrænsede dataopbevaringsperioder for børnebrugere
Begrænset databrug, der forbyder profilering eller adfærdsmålretning
Tydelige indikatorer, hvornår oplysninger vil blive delt med forældre
Ældre voksne og tilgængelighedshensyn
Ældre voksne og personer med handicap kan drage betydelige fordele af samtalegrænseflader, som ofte giver mere tilgængelige interaktionsmodeller end traditionelle computergrænseflader. De kan dog også stå over for særskilte privatlivsudfordringer:
Begrænset kendskab til teknologibegreber kan påvirke forståelsen af privatlivets fred
Kognitive svækkelser kan påvirke kapaciteten til komplekse privatlivsbeslutninger
Afhængighed af hjælpeteknologi kan reducere den praktiske mulighed for at afvise privatlivsvilkår
Sundhedsrelateret brug kan involvere særligt følsomme data
Delte enheder i plejemiljøer skaber komplekse samtykkescenarier
Ansvarligt design for disse befolkningsgrupper kræver tankevækkende indkvartering uden at gå på kompromis med handlekraft. Tilgange omfatter:
Multimodale fortrolighedsforklaringer, der præsenterer oplysninger i forskellige formater
Forenklede privatlivsvalg fokuserede på praktiske konsekvenser frem for tekniske detaljer
Udpegede betroede repræsentanter for privatlivsbeslutninger, når det er relevant
Forbedret sikkerhed for sundheds- og omsorgsrelaterede funktioner
Klar adskillelse mellem generel assistance og lægerådgivning
Digital Literacy og Privacy Divid
På tværs af aldersgrupper skaber forskellige niveauer af digital viden og fortrolighed om privatlivets fred, hvad forskere kalder "privatlivskløften" - hvor personer med større forståelse bedre kan beskytte deres information, mens andre forbliver mere sårbare. Samtalegrænseflader, selvom de potentielt er mere intuitive end traditionel computerbehandling, indlejrer stadig komplekse privatlivsimplikationer, som måske ikke er indlysende for alle brugere.
At bygge bro over denne kløft kræver tilgange, der gør privatlivets fred tilgængeligt uden at antage teknisk viden:
Privatlivsforklaringer, der fokuserer på konkrete resultater frem for tekniske mekanismer
Eksempler, der illustrerer potentielle privatlivsrisici i relaterbare scenarier
Progressiv afsløring, der introducerer begreber, efterhånden som de bliver relevante
Alternativer til teksttunge privatlivsoplysninger, herunder visuelle og lydformater
I sidste ende kræver det at skabe en virkelig inkluderende samtale-AI, at man anerkender, at privatlivsbehov og forståelse varierer betydeligt på tværs af populationer. One-size-fits-all tilgange efterlader uundgåeligt sårbare brugere med utilstrækkelig beskyttelse eller udelukket fra gavnlige teknologier. De mest etiske implementeringer anerkender disse forskelle og giver passende tilpasninger, samtidig med at respekten for individuel autonomi bevares.
Børn og privatliv
Børn repræsenterer en befolkning af særlig bekymring, da de måske ikke forstår konsekvenserne af privatlivets fred, men i stigende grad interagerer med samtalegrænseflader:
Mange børn mangler udviklingsevnen til at træffe informerede privatlivsbeslutninger
Børn kan dele information mere frit i samtale uden at forstå potentielle konsekvenser
Unge brugere skelner muligvis ikke mellem at tale med en AI og en betroet menneskelig fortrolig
Data indsamlet i barndommen kan potentielt følge individer i årtier
Regulatoriske rammer som COPPA i USA og GDPR's specifikke bestemmelser for børn etablerer basisbeskyttelse, men implementeringsudfordringer er stadig. Stemmegenkendelsesteknologi kan have svært ved at identificere børnebrugere pålideligt, hvilket komplicerer alderssvarende privatlivsforanstaltninger. Systemer, der primært er designet til voksne, forklarer muligvis ikke begreber om beskyttelse af personlige oplysninger tilstrækkeligt på et sprog, der er tilgængeligt for børn.
Udviklere, der skaber børnefokuseret samtale-AI eller funktioner, skal overveje specialiserede tilgange, herunder:
Standardindstillinger for høj privatliv med forældrekontrol til justeringer
Alderssvarende forklaringer af dataindsamling ved hjælp af konkrete eksempler
Begrænsede dataopbevaringsperioder for børnebrugere
Begrænset databrug, der forbyder profilering eller adfærdsmålretning
Tydelige indikatorer, hvornår oplysninger vil blive delt med forældre
Ældre voksne og tilgængelighedshensyn
Ældre voksne og personer med handicap kan drage betydelige fordele af samtalegrænseflader, som ofte giver mere tilgængelige interaktionsmodeller end traditionelle computergrænseflader. De kan dog også stå over for særskilte privatlivsudfordringer:
Begrænset kendskab til teknologibegreber kan påvirke forståelsen af privatlivets fred
Kognitive svækkelser kan påvirke kapaciteten til komplekse privatlivsbeslutninger
Afhængighed af hjælpeteknologi kan reducere den praktiske mulighed for at afvise privatlivsvilkår
Sundhedsrelateret brug kan involvere særligt følsomme data
Delte enheder i plejemiljøer skaber komplekse samtykkescenarier
Ansvarligt design for disse befolkningsgrupper kræver tankevækkende indkvartering uden at gå på kompromis med handlekraft. Tilgange omfatter:
Multimodale fortrolighedsforklaringer, der præsenterer oplysninger i forskellige formater
Forenklede privatlivsvalg fokuserede på praktiske konsekvenser frem for tekniske detaljer
Udpegede betroede repræsentanter for privatlivsbeslutninger, når det er relevant
Forbedret sikkerhed for sundheds- og omsorgsrelaterede funktioner
Klar adskillelse mellem generel assistance og lægerådgivning
Digital Literacy og Privacy Divid
På tværs af aldersgrupper skaber forskellige niveauer af digital viden og fortrolighed om privatlivets fred, hvad forskere kalder "privatlivskløften" - hvor personer med større forståelse bedre kan beskytte deres information, mens andre forbliver mere sårbare. Samtalegrænseflader, selvom de potentielt er mere intuitive end traditionel computerbehandling, indlejrer stadig komplekse privatlivsimplikationer, som måske ikke er indlysende for alle brugere.
At bygge bro over denne kløft kræver tilgange, der gør privatlivets fred tilgængeligt uden at antage teknisk viden:
Privatlivsforklaringer, der fokuserer på konkrete resultater frem for tekniske mekanismer
Eksempler, der illustrerer potentielle privatlivsrisici i relaterbare scenarier
Progressiv afsløring, der introducerer begreber, efterhånden som de bliver relevante
Alternativer til teksttunge privatlivsoplysninger, herunder visuelle og lydformater
I sidste ende kræver det at skabe en virkelig inkluderende samtale-AI, at man anerkender, at privatlivsbehov og forståelse varierer betydeligt på tværs af populationer. One-size-fits-all tilgange efterlader uundgåeligt sårbare brugere med utilstrækkelig beskyttelse eller udelukket fra gavnlige teknologier. De mest etiske implementeringer anerkender disse forskelle og giver passende tilpasninger, samtidig med at respekten for individuel autonomi bevares.
Forretningsmæssige overvejelser: Balancering af innovation og ansvar
For virksomheder, der udvikler eller implementerer samtale-AI, involverer det at navigere i privatlivsudfordringer komplekse strategiske beslutninger, der balancerer forretningsmål med etisk ansvar og lovmæssige krav.
Business-casen for privatlivscentreret design
Selvom beskyttelse af privatlivets fred kan synes at begrænse forretningsmuligheder ved første øjekast, anerkender fremsynede virksomheder i stigende grad forretningsværdien af stærk privatlivspraksis:
Tillid som konkurrencefordel – Efterhånden som bevidstheden om privatlivets fred vokser, bliver troværdig datapraksis en meningsfuld differentiator. Forskning viser konsekvent, at forbrugere foretrækker tjenester, de mener vil beskytte deres personlige oplysninger.
Regulatorisk overholdelseseffektivitet – Indbygning af privatliv i samtale-AI fra begyndelsen reducerer dyr eftermontering i takt med, at reglerne udvikler sig. Denne "privacy by design"-tilgang repræsenterer betydelige langsigtede besparelser sammenlignet med at adressere privatlivets fred som en eftertanke.
Risikobegrænsning – Databrud og privatlivsskandaler medfører betydelige omkostninger, fra lovgivningsmæssige sanktioner til skade på omdømme. Privatlivscentreret design reducerer disse risici gennem dataminimering og passende sikkerhedsforanstaltninger.
Markedsadgang – Stærk privatlivspraksis muliggør drift i regioner med strenge regler, hvilket udvider potentielle markeder uden at kræve flere produktversioner.
Disse faktorer skaber overbevisende forretningsincitamenter for privatlivsinvesteringer ud over overholdelse, især for samtale-AI, hvor tillid direkte påvirker brugernes vilje til at engagere sig i teknologien.
Strategiske tilgange til dataindsamling
Virksomheder skal træffe gennemtænkte beslutninger om, hvilke data deres samtalesystemer indsamler, og hvordan de bruges:
Funktionel minimalisme – Indsamling af kun data, der er direkte nødvendige for den ønskede funktionalitet, med klare grænser mellem væsentlig og valgfri dataindsamling.
Formålsspecificitet – Definition af snævre, eksplicitte formål for databrug frem for bred, åben indsamling, der kan tjene fremtidige uspecificerede behov.
Gennemsigtighedsdifferentiering – Klar skelnen mellem data brugt til øjeblikkelig funktionalitet versus systemforbedring, hvilket giver brugerne separat kontrol over disse forskellige anvendelser.
Privatlivsniveauer - Tilbyder servicemuligheder med forskellige afvejninger af privatliv/funktionalitet, så brugerne kan vælge deres foretrukne balance.
Disse tilgange hjælper virksomheder med at undgå "indsaml alt muligt"-tankegangen, der skaber både privatlivsrisici og potentiel regulatorisk eksponering.
Afbalancering af førsteparts- og tredjepartsintegration
Samtaleplatforme fungerer ofte som indgange til bredere serviceøkosystemer, hvilket rejser spørgsmål om datadeling og integration:
Hvordan skal brugersamtykke administreres, når samtaler spænder over flere tjenester?
Hvem har ansvaret for beskyttelse af privatlivets fred på tværs af integrerede oplevelser?
Hvordan kan privatlivsforventninger opretholdes konsekvent på tværs af et økosystem?
Hvilke privatlivsoplysninger skal deles mellem integrationspartnere?
Førende virksomheder tackler disse udfordringer gennem klare partnerkrav, standardiserede privatlivsgrænseflader og gennemsigtig offentliggørelse af datastrømme mellem tjenester. Nogle implementerer "privatlivsernæringsmærker", der hurtigt kommunikerer væsentlige privatlivsoplysninger, før brugere interagerer med tredjepartstjenester gennem deres samtaleplatforme.
Oprettelse af bæredygtig dataforvaltning
Effektiv beskyttelse af privatlivets fred kræver robuste styringsstrukturer, der balancerer innovationsbehov med privatlivsansvar:
Tværfunktionelle privatlivsteams, der inkluderer produkt-, ingeniør-, juridiske og etiske perspektiver
Konsekvensvurderinger af privatlivets fred udført tidligt i produktudviklingen
Regelmæssige privatlivsrevisioner for at verificere overholdelse af angivne politikker
Tydelige ansvarlighedsstrukturer, der definerer privatlivsansvar på tværs af organisationen
Etiske udvalg, der behandler nye privatlivsspørgsmål, der opstår i samtalesammenhænge
Disse styringsmekanismer hjælper med at sikre, at privatlivsovervejelser er integreret gennem hele udviklingsprocessen i stedet for kun at blive behandlet i de endelige revisionsstadier, når ændringer bliver dyre.
For virksomheder, der investerer i konversations-AI, bør privatlivets fred ikke ses som en overholdelsesbyrde, men som et grundlæggende element i bæredygtig innovation. Virksomheder, der etablerer troværdig privatlivspraksis, skaber betingelserne for bredere accept og adoption af deres samtaleteknologier, hvilket i sidste ende muliggør mere værdifulde brugerforhold.
Business-casen for privatlivscentreret design
Selvom beskyttelse af privatlivets fred kan synes at begrænse forretningsmuligheder ved første øjekast, anerkender fremsynede virksomheder i stigende grad forretningsværdien af stærk privatlivspraksis:
Tillid som konkurrencefordel – Efterhånden som bevidstheden om privatlivets fred vokser, bliver troværdig datapraksis en meningsfuld differentiator. Forskning viser konsekvent, at forbrugere foretrækker tjenester, de mener vil beskytte deres personlige oplysninger.
Regulatorisk overholdelseseffektivitet – Indbygning af privatliv i samtale-AI fra begyndelsen reducerer dyr eftermontering i takt med, at reglerne udvikler sig. Denne "privacy by design"-tilgang repræsenterer betydelige langsigtede besparelser sammenlignet med at adressere privatlivets fred som en eftertanke.
Risikobegrænsning – Databrud og privatlivsskandaler medfører betydelige omkostninger, fra lovgivningsmæssige sanktioner til skade på omdømme. Privatlivscentreret design reducerer disse risici gennem dataminimering og passende sikkerhedsforanstaltninger.
Markedsadgang – Stærk privatlivspraksis muliggør drift i regioner med strenge regler, hvilket udvider potentielle markeder uden at kræve flere produktversioner.
Disse faktorer skaber overbevisende forretningsincitamenter for privatlivsinvesteringer ud over overholdelse, især for samtale-AI, hvor tillid direkte påvirker brugernes vilje til at engagere sig i teknologien.
Strategiske tilgange til dataindsamling
Virksomheder skal træffe gennemtænkte beslutninger om, hvilke data deres samtalesystemer indsamler, og hvordan de bruges:
Funktionel minimalisme – Indsamling af kun data, der er direkte nødvendige for den ønskede funktionalitet, med klare grænser mellem væsentlig og valgfri dataindsamling.
Formålsspecificitet – Definition af snævre, eksplicitte formål for databrug frem for bred, åben indsamling, der kan tjene fremtidige uspecificerede behov.
Gennemsigtighedsdifferentiering – Klar skelnen mellem data brugt til øjeblikkelig funktionalitet versus systemforbedring, hvilket giver brugerne separat kontrol over disse forskellige anvendelser.
Privatlivsniveauer - Tilbyder servicemuligheder med forskellige afvejninger af privatliv/funktionalitet, så brugerne kan vælge deres foretrukne balance.
Disse tilgange hjælper virksomheder med at undgå "indsaml alt muligt"-tankegangen, der skaber både privatlivsrisici og potentiel regulatorisk eksponering.
Afbalancering af førsteparts- og tredjepartsintegration
Samtaleplatforme fungerer ofte som indgange til bredere serviceøkosystemer, hvilket rejser spørgsmål om datadeling og integration:
Hvordan skal brugersamtykke administreres, når samtaler spænder over flere tjenester?
Hvem har ansvaret for beskyttelse af privatlivets fred på tværs af integrerede oplevelser?
Hvordan kan privatlivsforventninger opretholdes konsekvent på tværs af et økosystem?
Hvilke privatlivsoplysninger skal deles mellem integrationspartnere?
Førende virksomheder tackler disse udfordringer gennem klare partnerkrav, standardiserede privatlivsgrænseflader og gennemsigtig offentliggørelse af datastrømme mellem tjenester. Nogle implementerer "privatlivsernæringsmærker", der hurtigt kommunikerer væsentlige privatlivsoplysninger, før brugere interagerer med tredjepartstjenester gennem deres samtaleplatforme.
Oprettelse af bæredygtig dataforvaltning
Effektiv beskyttelse af privatlivets fred kræver robuste styringsstrukturer, der balancerer innovationsbehov med privatlivsansvar:
Tværfunktionelle privatlivsteams, der inkluderer produkt-, ingeniør-, juridiske og etiske perspektiver
Konsekvensvurderinger af privatlivets fred udført tidligt i produktudviklingen
Regelmæssige privatlivsrevisioner for at verificere overholdelse af angivne politikker
Tydelige ansvarlighedsstrukturer, der definerer privatlivsansvar på tværs af organisationen
Etiske udvalg, der behandler nye privatlivsspørgsmål, der opstår i samtalesammenhænge
Disse styringsmekanismer hjælper med at sikre, at privatlivsovervejelser er integreret gennem hele udviklingsprocessen i stedet for kun at blive behandlet i de endelige revisionsstadier, når ændringer bliver dyre.
For virksomheder, der investerer i konversations-AI, bør privatlivets fred ikke ses som en overholdelsesbyrde, men som et grundlæggende element i bæredygtig innovation. Virksomheder, der etablerer troværdig privatlivspraksis, skaber betingelserne for bredere accept og adoption af deres samtaleteknologier, hvilket i sidste ende muliggør mere værdifulde brugerforhold.
Brugeruddannelse og empowerment: Beyond Privacy Policys
At skabe virkelig privatlivsrespekterende samtale-AI kræver, at man bevæger sig ud over traditionelle fortrolighedsmeddelelser for aktivt at uddanne og give brugerne mulighed for at træffe informerede valg om deres data.
Begrænsningerne ved traditionel privatlivskommunikation
Standardtilgange til privatlivskommunikation kommer især til kort for samtalegrænseflader:
Privatlivspolitikker læses sjældent og er ofte skrevet i komplekst juridisk sprog
Traditionelle grænseflader til privatlivsstyring oversættes ikke godt til tale-først-interaktioner
Engangssamtykke omhandler ikke den igangværende, udviklende karakter af samtalerelationer
Tekniske fortrolighedsforklaringer kommunikerer ofte ikke praktiske konsekvenser for brugerne
Disse begrænsninger skaber en situation, hvor formel overholdelse kan opnås (brugere "accepterede" vilkårene) uden meningsfuldt informeret samtykke. Brugere forstår muligvis ikke, hvilke data der indsamles, hvordan de bruges, eller hvilken kontrol de har over deres oplysninger.
Oprettelse af meningsfuld fortrolighedskompetence
Mere effektive tilgange fokuserer på at opbygge ægte fortrolighedsforståelse gennem:
Just-in-time uddannelse, der giver relevante oplysninger om privatlivets fred på vigtige tidspunkter i stedet for alle på én gang
Klarsprogede forklaringer, der fokuserer på praktiske resultater frem for tekniske mekanismer
Konkrete eksempler, der illustrerer, hvordan data kan bruges og potentielle konsekvenser for privatlivets fred
Interaktive demonstrationer, der gør fortrolighedskoncepter håndgribelige snarere end abstrakte
Kontekstuelle påmindelser om, hvilke data der indsamles under forskellige typer interaktioner
Disse tilgange anerkender, at fortrolighed om privatlivets fred udvikler sig gradvist gennem gentagen eksponering og praktisk erfaring, ikke gennem engangsinformationsdumps.
Design til agentur og kontrol
Ud over uddannelse har brugerne brug for faktisk kontrol over deres information. Effektive tilgange omfatter:
Granulære tilladelser, der giver brugerne mulighed for at godkende specifikke anvendelser i stedet for alt-eller-intet-samtykke
Privacy-dashboards giver klar visualisering af, hvilke data der er blevet indsamlet
Simple sletningsmuligheder for at fjerne historiske oplysninger
Brugsindsigt, der viser, hvordan personlige data påvirker systemets adfærd
Privatlivsgenveje til hurtig justering af almindelige indstillinger
Regelmæssige indtjekninger til privatlivets fred beder om gennemgang af aktuelle indstillinger og dataindsamling
Kritisk er det, at disse kontrolelementer skal være let tilgængelige gennem selve samtalegrænsefladen, ikke begravet i separate websteder eller applikationer, der skaber friktion for brugere, der bruger stemme først.
Fællesskabsstandarder og sociale normer
Efterhånden som konversations-AI bliver mere udbredt, spiller fællesskabsstandarder og sociale normer en stadig vigtigere rolle i udformningen af forventninger til privatlivets fred. Virksomheder kan bidrage til sund normudvikling ved at:
Facilitering af bruger-til-bruger privatlivsundervisning gennem fællesskabsfora og videndeling
Fremhæv bedste praksis for privatliv og anerkendelse af brugere, der beskæftiger dem
Skaber gennemsigtighed omkring aggregerede privatlivsvalg for at hjælpe brugere med at forstå fællesskabsnormer
Engagere brugere i udvikling af privatlivsfunktioner gennem feedback og co-design
Disse tilgange anerkender, at privatlivets fred ikke blot er et individuelt anliggende, men en social konstruktion, der udvikles gennem kollektiv forståelse og praksis.
For at konversations-AI kan opnå sit fulde potentiale og samtidig respektere individuelle rettigheder, skal brugerne blive informerede deltagere i stedet for passive emner for dataindsamling. Dette kræver vedvarende investeringer i uddannelse og empowerment snarere end minimal overholdelse af offentliggørelse. Virksomheder, der fører an på dette område, styrker brugerrelationer og bidrager samtidig til et sundere overordnet økosystem for samtaleteknologi.
Begrænsningerne ved traditionel privatlivskommunikation
Standardtilgange til privatlivskommunikation kommer især til kort for samtalegrænseflader:
Privatlivspolitikker læses sjældent og er ofte skrevet i komplekst juridisk sprog
Traditionelle grænseflader til privatlivsstyring oversættes ikke godt til tale-først-interaktioner
Engangssamtykke omhandler ikke den igangværende, udviklende karakter af samtalerelationer
Tekniske fortrolighedsforklaringer kommunikerer ofte ikke praktiske konsekvenser for brugerne
Disse begrænsninger skaber en situation, hvor formel overholdelse kan opnås (brugere "accepterede" vilkårene) uden meningsfuldt informeret samtykke. Brugere forstår muligvis ikke, hvilke data der indsamles, hvordan de bruges, eller hvilken kontrol de har over deres oplysninger.
Oprettelse af meningsfuld fortrolighedskompetence
Mere effektive tilgange fokuserer på at opbygge ægte fortrolighedsforståelse gennem:
Just-in-time uddannelse, der giver relevante oplysninger om privatlivets fred på vigtige tidspunkter i stedet for alle på én gang
Klarsprogede forklaringer, der fokuserer på praktiske resultater frem for tekniske mekanismer
Konkrete eksempler, der illustrerer, hvordan data kan bruges og potentielle konsekvenser for privatlivets fred
Interaktive demonstrationer, der gør fortrolighedskoncepter håndgribelige snarere end abstrakte
Kontekstuelle påmindelser om, hvilke data der indsamles under forskellige typer interaktioner
Disse tilgange anerkender, at fortrolighed om privatlivets fred udvikler sig gradvist gennem gentagen eksponering og praktisk erfaring, ikke gennem engangsinformationsdumps.
Design til agentur og kontrol
Ud over uddannelse har brugerne brug for faktisk kontrol over deres information. Effektive tilgange omfatter:
Granulære tilladelser, der giver brugerne mulighed for at godkende specifikke anvendelser i stedet for alt-eller-intet-samtykke
Privacy-dashboards giver klar visualisering af, hvilke data der er blevet indsamlet
Simple sletningsmuligheder for at fjerne historiske oplysninger
Brugsindsigt, der viser, hvordan personlige data påvirker systemets adfærd
Privatlivsgenveje til hurtig justering af almindelige indstillinger
Regelmæssige indtjekninger til privatlivets fred beder om gennemgang af aktuelle indstillinger og dataindsamling
Kritisk er det, at disse kontrolelementer skal være let tilgængelige gennem selve samtalegrænsefladen, ikke begravet i separate websteder eller applikationer, der skaber friktion for brugere, der bruger stemme først.
Fællesskabsstandarder og sociale normer
Efterhånden som konversations-AI bliver mere udbredt, spiller fællesskabsstandarder og sociale normer en stadig vigtigere rolle i udformningen af forventninger til privatlivets fred. Virksomheder kan bidrage til sund normudvikling ved at:
Facilitering af bruger-til-bruger privatlivsundervisning gennem fællesskabsfora og videndeling
Fremhæv bedste praksis for privatliv og anerkendelse af brugere, der beskæftiger dem
Skaber gennemsigtighed omkring aggregerede privatlivsvalg for at hjælpe brugere med at forstå fællesskabsnormer
Engagere brugere i udvikling af privatlivsfunktioner gennem feedback og co-design
Disse tilgange anerkender, at privatlivets fred ikke blot er et individuelt anliggende, men en social konstruktion, der udvikles gennem kollektiv forståelse og praksis.
For at konversations-AI kan opnå sit fulde potentiale og samtidig respektere individuelle rettigheder, skal brugerne blive informerede deltagere i stedet for passive emner for dataindsamling. Dette kræver vedvarende investeringer i uddannelse og empowerment snarere end minimal overholdelse af offentliggørelse. Virksomheder, der fører an på dette område, styrker brugerrelationer og bidrager samtidig til et sundere overordnet økosystem for samtaleteknologi.
Nye løsninger og bedste praksis
Efterhånden som bevidstheden om samtale-AI-privatlivsudfordringer vokser, dukker innovative tilgange op til at imødegå disse bekymringer og samtidig bevare nyttig funktionalitet.
Privatlivsforbedrende teknologier til Conversational AI
Tekniske innovationer, der specifikt retter sig mod privatlivets fred i samtalesammenhænge, omfatter:
Lokale behandlingsenklaver, der udfører følsomme beregninger på enheden i sikre miljøer isoleret fra andre applikationer
Homomorfe krypteringsteknikker, der muliggør behandling af krypterede data uden dekryptering, hvilket muliggør privatlivsbevarende analyse
Syntetiske træningsdata genereret for at opretholde statistiske egenskaber for rigtige samtaler uden at afsløre faktiske brugerinteraktioner
Privatlivsbevarende transskription, der konverterer tale til tekst lokalt, før du sender minimerede tekstdata til behandling
Fødereret læringsimplementeringer specifikt optimeret til den distribuerede karakter af samtaleenheder
Disse teknologier er på forskellige modenhedsstadier, hvor nogle allerede optræder i kommercielle produkter, mens andre primært forbliver i forskningsfaser.
Branchestandarder og rammer
Den konverserende AI-industri udvikler fælles standarder og rammer for at etablere konsistente tilgange til beskyttelse af personlige oplysninger:
Voice Privacy Alliance har foreslået standardiserede fortrolighedskontroller og oplysningsformater for stemmeassistenter
IEEE har arbejdsgrupper, der udvikler tekniske standarder for privatliv i talte grænseflader
Open Voice Network er ved at skabe interoperabilitetsstandarder, der omfatter krav til beskyttelse af personlige oplysninger
Forskellige brancheforeninger har offentliggjort bedste praksis for privatliv, der er specifikke for samtalekontekster
Disse samarbejdsbestræbelser sigter mod at etablere grundlæggende forventninger til beskyttelse af personlige oplysninger, der forenkler overholdelse for udviklere, samtidig med at de sikrer ensartede brugeroplevelser på tværs af platforme.
Designmønstre til privatlivsrespekterende samtale-UX
Brugeroplevelsesdesignere udvikler specialiserede mønstre til håndtering af privatliv i samtalegrænseflader:
Progressiv offentliggørelse af privatlivets fred, der introducerer oplysninger i håndterbare segmenter
Omgivende privatlivsindikatorer bruger subtile lyd- eller visuelle signaler til at indikere, når systemerne lytter eller behandler
Samtykkeskoreografi, der designer tilladelsesanmodninger med en naturlig følelse, der ikke forstyrrer samtaleflowet
Privatlivsbevarende standardindstillinger, der starter med minimal dataindsamling og kun udvides med eksplicit brugergodkendelse
At glemme mekanismer, der gør dataudløb og sletning til en integreret del af interaktionsmodellen
Disse designmønstre sigter mod at gøre privatlivsovervejelser til en integreret del af samtaleoplevelsen snarere end et separat lag af overholdelseskrav.
Organisatorisk bedste praksis
Organisationer, der er førende inden for konversations-AI, der respekterer privatlivets fred, implementerer typisk flere nøglepraksis:
Forkæmpere for beskyttelse af personlige oplysninger indlejret i udviklingsteams, ikke kun i juridiske afdelinger
Regelmæssige risikovurderinger af privatlivets fred gennem hele udviklingens livscyklus
Privatlivsfokuseret brugertest, der eksplicit evaluerer fortrolighedsforståelse og -kontrol
Gennemsigtighedsrapporter giver indsigt i datapraksis og offentlige anmodninger om oplysninger
Eksterne revisioner af privatlivets fred, der validerer, at faktisk praksis matcher angivne politikker
Privacy bug bounty-programmer, der tilskynder til identifikation af privatlivssårbarheder
Disse organisatoriske tilgange sikrer, at privatlivsovervejelser forbliver centrale i hele produktudviklingen frem for at blive eftertanke under juridisk gennemgang.
For udviklere og virksomheder, der arbejder i dette område, giver disse nye løsninger værdifuld retning for at skabe samtale-AI, der respekterer privatlivets fred og samtidig leverer overbevisende brugeroplevelser. Selvom ingen enkelt tilgang løser alle privatlivsudfordringer, kan en tankevækkende kombination af teknisk, design og organisatorisk praksis forbedre privatlivets resultater væsentligt.
Privatlivsforbedrende teknologier til Conversational AI
Tekniske innovationer, der specifikt retter sig mod privatlivets fred i samtalesammenhænge, omfatter:
Lokale behandlingsenklaver, der udfører følsomme beregninger på enheden i sikre miljøer isoleret fra andre applikationer
Homomorfe krypteringsteknikker, der muliggør behandling af krypterede data uden dekryptering, hvilket muliggør privatlivsbevarende analyse
Syntetiske træningsdata genereret for at opretholde statistiske egenskaber for rigtige samtaler uden at afsløre faktiske brugerinteraktioner
Privatlivsbevarende transskription, der konverterer tale til tekst lokalt, før du sender minimerede tekstdata til behandling
Fødereret læringsimplementeringer specifikt optimeret til den distribuerede karakter af samtaleenheder
Disse teknologier er på forskellige modenhedsstadier, hvor nogle allerede optræder i kommercielle produkter, mens andre primært forbliver i forskningsfaser.
Branchestandarder og rammer
Den konverserende AI-industri udvikler fælles standarder og rammer for at etablere konsistente tilgange til beskyttelse af personlige oplysninger:
Voice Privacy Alliance har foreslået standardiserede fortrolighedskontroller og oplysningsformater for stemmeassistenter
IEEE har arbejdsgrupper, der udvikler tekniske standarder for privatliv i talte grænseflader
Open Voice Network er ved at skabe interoperabilitetsstandarder, der omfatter krav til beskyttelse af personlige oplysninger
Forskellige brancheforeninger har offentliggjort bedste praksis for privatliv, der er specifikke for samtalekontekster
Disse samarbejdsbestræbelser sigter mod at etablere grundlæggende forventninger til beskyttelse af personlige oplysninger, der forenkler overholdelse for udviklere, samtidig med at de sikrer ensartede brugeroplevelser på tværs af platforme.
Designmønstre til privatlivsrespekterende samtale-UX
Brugeroplevelsesdesignere udvikler specialiserede mønstre til håndtering af privatliv i samtalegrænseflader:
Progressiv offentliggørelse af privatlivets fred, der introducerer oplysninger i håndterbare segmenter
Omgivende privatlivsindikatorer bruger subtile lyd- eller visuelle signaler til at indikere, når systemerne lytter eller behandler
Samtykkeskoreografi, der designer tilladelsesanmodninger med en naturlig følelse, der ikke forstyrrer samtaleflowet
Privatlivsbevarende standardindstillinger, der starter med minimal dataindsamling og kun udvides med eksplicit brugergodkendelse
At glemme mekanismer, der gør dataudløb og sletning til en integreret del af interaktionsmodellen
Disse designmønstre sigter mod at gøre privatlivsovervejelser til en integreret del af samtaleoplevelsen snarere end et separat lag af overholdelseskrav.
Organisatorisk bedste praksis
Organisationer, der er førende inden for konversations-AI, der respekterer privatlivets fred, implementerer typisk flere nøglepraksis:
Forkæmpere for beskyttelse af personlige oplysninger indlejret i udviklingsteams, ikke kun i juridiske afdelinger
Regelmæssige risikovurderinger af privatlivets fred gennem hele udviklingens livscyklus
Privatlivsfokuseret brugertest, der eksplicit evaluerer fortrolighedsforståelse og -kontrol
Gennemsigtighedsrapporter giver indsigt i datapraksis og offentlige anmodninger om oplysninger
Eksterne revisioner af privatlivets fred, der validerer, at faktisk praksis matcher angivne politikker
Privacy bug bounty-programmer, der tilskynder til identifikation af privatlivssårbarheder
Disse organisatoriske tilgange sikrer, at privatlivsovervejelser forbliver centrale i hele produktudviklingen frem for at blive eftertanke under juridisk gennemgang.
For udviklere og virksomheder, der arbejder i dette område, giver disse nye løsninger værdifuld retning for at skabe samtale-AI, der respekterer privatlivets fred og samtidig leverer overbevisende brugeroplevelser. Selvom ingen enkelt tilgang løser alle privatlivsudfordringer, kan en tankevækkende kombination af teknisk, design og organisatorisk praksis forbedre privatlivets resultater væsentligt.
Fremtiden for privatliv i Conversational AI
As we look ahead, several trends are likely to shape the evolving relationship between conversational AI and privacy.
From Centralized to Distributed Intelligence
The architecture of conversational AI systems is increasingly shifting from fully cloud-based approaches toward more distributed models:
Personal AI agents that run primarily on user devices, maintaining private knowledge bases about individual preferences and patterns
Hybrid processing systems that handle sensitive functions locally while leveraging cloud resources for compute-intensive tasks
User-controlled cloud instances where individuals own their data and the processing resources that operate on it
Decentralized learning approaches that improve AI systems without centralizing user data
These architectural shifts fundamentally change the privacy equation by keeping more personal data under user control rather than aggregating it in centralized corporate repositories.
Evolving Regulatory Approaches
Privacy regulation for conversational AI continues to develop, with several emerging trends:
AI-specific regulations that address unique challenges beyond general data protection frameworks
Global convergence around core privacy principles despite regional variations in specific requirements
Certification programs providing standardized ways to verify privacy protections
Algorithmic transparency requirements mandating explanation of how AI systems use personal data
These regulatory developments will likely establish clearer boundaries for conversational AI while potentially creating more predictable compliance environments for developers.
Shifting User Expectations
User attitudes toward privacy in conversational contexts are evolving as experience with these technologies grows:
Increasing sophistication about privacy trade-offs and the value of personal data
Greater demand for transparency about how conversational data improves AI systems
Rising expectations for granular control over different types of personal information
Growing concern about emotional and psychological profiles created through conversation analysis
These evolving attitudes will shape market demand for privacy features and potentially reward companies that offer stronger protections.
Ethical AI and Value Alignment
Beyond legal compliance, conversational AI is increasingly evaluated against broader ethical frameworks:
Value alignment ensuring AI systems respect user privacy values even when not legally required
Distributive justice addressing privacy disparities across different user groups
Intergenerational equity considering long-term privacy implications of data collected today
Collective privacy interests recognizing that individual privacy choices affect broader communities
These ethical considerations extend privacy discussions beyond individual rights to consider societal impacts and collective interests that may not be fully addressed by individual choice frameworks.
Privacy as Competitive Advantage
As privacy awareness grows, market dynamics around conversational AI are evolving:
Privacy-focused alternatives gaining traction against data-intensive incumbents
Premium positioning for high-privacy options in various market segments
Increased investment in privacy-enhancing technologies to enable differentiation
Enterprise buyers prioritizing privacy features in procurement decisions
These market forces create economic incentives for privacy innovation beyond regulatory compliance, potentially accelerating development of privacy-respecting alternatives.
The future of privacy in conversational AI will be shaped by the interplay of these technological, regulatory, social, and market forces. While perfect privacy solutions remain elusive, the direction of development suggests increasing options for users who seek more privacy-respecting conversational experiences.
For developers, businesses, and users engaged with these systems, staying informed about emerging approaches and actively participating in shaping privacy norms and expectations will be essential as conversational AI becomes an increasingly central part of our digital lives.
Conclusion: Toward Responsible Conversational AI
As conversational AI continues its rapid evolution and integration into our daily lives, the privacy challenges we've explored take on increasing urgency. These systems promise tremendous benefits—more natural human-computer interaction, accessibility for those who struggle with traditional interfaces, and assistance that adapts to individual needs. Realizing these benefits while protecting fundamental privacy rights requires thoughtful navigation of complex trade-offs.
The path forward isn't about choosing between functionality and privacy as mutually exclusive options. Rather, it involves creative problem-solving to design systems that deliver valuable capabilities while respecting privacy boundaries. This requires technical innovation, thoughtful design, organizational commitment, and appropriate regulation working in concert.
For developers, the challenge lies in creating systems that collect only necessary data, process it with appropriate safeguards, and provide meaningful transparency and control. For businesses, it means recognizing privacy as a core value proposition rather than a compliance burden. For users, it involves becoming more informed about privacy implications and expressing preferences through both settings choices and market decisions.
Perhaps most importantly, advancing privacy-respecting conversational AI requires ongoing dialogue between all stakeholders—technologists, businesses, policymakers, privacy advocates, and users themselves. These conversations need to address not just what's technically possible or legally required, but what kind of relationship we want with the increasingly intelligent systems that mediate our digital experiences.
The decisions we make today about conversational AI privacy will shape not just current products but the trajectory of human-AI interaction for years to come. By approaching these challenges thoughtfully, we can create conversational systems that earn trust through respect for privacy rather than demanding trust despite privacy concerns.
The most successful conversational AI won't be the systems that collect the most data or even those that provide the most functionality, but those that strike a thoughtful balance—delivering valuable assistance while respecting the fundamental human need for privacy and control over personal information. Achieving this balance is not just good ethics; it's the foundation for sustainable, beneficial AI that serves human flourishing.
From Centralized to Distributed Intelligence
The architecture of conversational AI systems is increasingly shifting from fully cloud-based approaches toward more distributed models:
Personal AI agents that run primarily on user devices, maintaining private knowledge bases about individual preferences and patterns
Hybrid processing systems that handle sensitive functions locally while leveraging cloud resources for compute-intensive tasks
User-controlled cloud instances where individuals own their data and the processing resources that operate on it
Decentralized learning approaches that improve AI systems without centralizing user data
These architectural shifts fundamentally change the privacy equation by keeping more personal data under user control rather than aggregating it in centralized corporate repositories.
Evolving Regulatory Approaches
Privacy regulation for conversational AI continues to develop, with several emerging trends:
AI-specific regulations that address unique challenges beyond general data protection frameworks
Global convergence around core privacy principles despite regional variations in specific requirements
Certification programs providing standardized ways to verify privacy protections
Algorithmic transparency requirements mandating explanation of how AI systems use personal data
These regulatory developments will likely establish clearer boundaries for conversational AI while potentially creating more predictable compliance environments for developers.
Shifting User Expectations
User attitudes toward privacy in conversational contexts are evolving as experience with these technologies grows:
Increasing sophistication about privacy trade-offs and the value of personal data
Greater demand for transparency about how conversational data improves AI systems
Rising expectations for granular control over different types of personal information
Growing concern about emotional and psychological profiles created through conversation analysis
These evolving attitudes will shape market demand for privacy features and potentially reward companies that offer stronger protections.
Ethical AI and Value Alignment
Beyond legal compliance, conversational AI is increasingly evaluated against broader ethical frameworks:
Value alignment ensuring AI systems respect user privacy values even when not legally required
Distributive justice addressing privacy disparities across different user groups
Intergenerational equity considering long-term privacy implications of data collected today
Collective privacy interests recognizing that individual privacy choices affect broader communities
These ethical considerations extend privacy discussions beyond individual rights to consider societal impacts and collective interests that may not be fully addressed by individual choice frameworks.
Privacy as Competitive Advantage
As privacy awareness grows, market dynamics around conversational AI are evolving:
Privacy-focused alternatives gaining traction against data-intensive incumbents
Premium positioning for high-privacy options in various market segments
Increased investment in privacy-enhancing technologies to enable differentiation
Enterprise buyers prioritizing privacy features in procurement decisions
These market forces create economic incentives for privacy innovation beyond regulatory compliance, potentially accelerating development of privacy-respecting alternatives.
The future of privacy in conversational AI will be shaped by the interplay of these technological, regulatory, social, and market forces. While perfect privacy solutions remain elusive, the direction of development suggests increasing options for users who seek more privacy-respecting conversational experiences.
For developers, businesses, and users engaged with these systems, staying informed about emerging approaches and actively participating in shaping privacy norms and expectations will be essential as conversational AI becomes an increasingly central part of our digital lives.
Conclusion: Toward Responsible Conversational AI
As conversational AI continues its rapid evolution and integration into our daily lives, the privacy challenges we've explored take on increasing urgency. These systems promise tremendous benefits—more natural human-computer interaction, accessibility for those who struggle with traditional interfaces, and assistance that adapts to individual needs. Realizing these benefits while protecting fundamental privacy rights requires thoughtful navigation of complex trade-offs.
The path forward isn't about choosing between functionality and privacy as mutually exclusive options. Rather, it involves creative problem-solving to design systems that deliver valuable capabilities while respecting privacy boundaries. This requires technical innovation, thoughtful design, organizational commitment, and appropriate regulation working in concert.
For developers, the challenge lies in creating systems that collect only necessary data, process it with appropriate safeguards, and provide meaningful transparency and control. For businesses, it means recognizing privacy as a core value proposition rather than a compliance burden. For users, it involves becoming more informed about privacy implications and expressing preferences through both settings choices and market decisions.
Perhaps most importantly, advancing privacy-respecting conversational AI requires ongoing dialogue between all stakeholders—technologists, businesses, policymakers, privacy advocates, and users themselves. These conversations need to address not just what's technically possible or legally required, but what kind of relationship we want with the increasingly intelligent systems that mediate our digital experiences.
The decisions we make today about conversational AI privacy will shape not just current products but the trajectory of human-AI interaction for years to come. By approaching these challenges thoughtfully, we can create conversational systems that earn trust through respect for privacy rather than demanding trust despite privacy concerns.
The most successful conversational AI won't be the systems that collect the most data or even those that provide the most functionality, but those that strike a thoughtful balance—delivering valuable assistance while respecting the fundamental human need for privacy and control over personal information. Achieving this balance is not just good ethics; it's the foundation for sustainable, beneficial AI that serves human flourishing.