Test AI på DIN hjemmeside på 60 sekunder
Se hvordan vores AI øjeblikkeligt analyserer din hjemmeside og skaber en personlig chatbot - uden registrering. Indtast blot din URL og se den arbejde!
Klar på 60 sekunder
Ingen kodning påkrævet
100% sikker
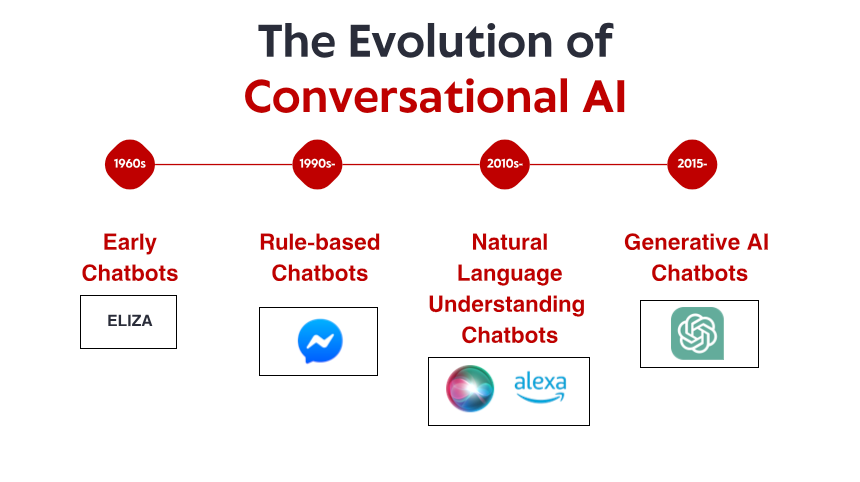
Den ydmyge begyndelse: Tidlige regelbaserede systemer
Historien om samtale-AI begynder i 1960'erne, længe før smartphones og stemmeassistenter blev husholdningsartikler. I et lille laboratorium på MIT skabte datalog Joseph Weizenbaum, hvad mange betragter som den første chatbot: ELIZA. Designet til at simulere en Rogeriansk psykoterapeut, arbejdede ELIZA gennem simple mønstermatching og substitutionsregler. Når en bruger skrev "Jeg føler mig ked af det", svarer ELIZA måske med "Hvorfor føler du dig ked af det?" – skabe illusionen om forståelse ved at omformulere udsagn som spørgsmål.
Det, der gjorde ELIZA bemærkelsesværdig, var ikke dens tekniske sofistikering – efter nutidens standarder var programmet utroligt grundlæggende. Det var snarere den dybe virkning, det havde på brugerne. På trods af at de vidste, at de talte til et computerprogram uden egentlig forståelse, dannede mange mennesker følelsesmæssige forbindelser med ELIZA og delte dybt personlige tanker og følelser. Dette fænomen, som Weizenbaum selv fandt foruroligende, afslørede noget grundlæggende om menneskets psykologi og vores vilje til at antropomorfisere selv de enkleste samtalegrænseflader.
Igennem 1970'erne og 1980'erne fulgte regelbaserede chatbots ELIZAs skabelon med trinvise forbedringer. Programmer som PARRY (simulering af en paranoid skizofren) og RACTER (som "forfattede" en bog kaldet "Politimandens skæg er halvt konstrueret") forblev fast inden for det regelbaserede paradigme – ved hjælp af foruddefinerede mønstre, søgeordsmatching og skabelonsvar.
Disse tidlige systemer havde alvorlige begrænsninger. De kunne faktisk ikke forstå sprog, lære af interaktioner eller tilpasse sig uventede input. Deres viden var begrænset til de regler, som deres programmører eksplicit havde defineret. Når brugere uundgåeligt forvildede sig uden for disse grænser, knuste illusionen om intelligens hurtigt og afslørede den mekaniske natur nedenunder. På trods af disse begrænsninger etablerede disse banebrydende systemer grundlaget, som al fremtidig samtale-AI ville bygge på.
Det, der gjorde ELIZA bemærkelsesværdig, var ikke dens tekniske sofistikering – efter nutidens standarder var programmet utroligt grundlæggende. Det var snarere den dybe virkning, det havde på brugerne. På trods af at de vidste, at de talte til et computerprogram uden egentlig forståelse, dannede mange mennesker følelsesmæssige forbindelser med ELIZA og delte dybt personlige tanker og følelser. Dette fænomen, som Weizenbaum selv fandt foruroligende, afslørede noget grundlæggende om menneskets psykologi og vores vilje til at antropomorfisere selv de enkleste samtalegrænseflader.
Igennem 1970'erne og 1980'erne fulgte regelbaserede chatbots ELIZAs skabelon med trinvise forbedringer. Programmer som PARRY (simulering af en paranoid skizofren) og RACTER (som "forfattede" en bog kaldet "Politimandens skæg er halvt konstrueret") forblev fast inden for det regelbaserede paradigme – ved hjælp af foruddefinerede mønstre, søgeordsmatching og skabelonsvar.
Disse tidlige systemer havde alvorlige begrænsninger. De kunne faktisk ikke forstå sprog, lære af interaktioner eller tilpasse sig uventede input. Deres viden var begrænset til de regler, som deres programmører eksplicit havde defineret. Når brugere uundgåeligt forvildede sig uden for disse grænser, knuste illusionen om intelligens hurtigt og afslørede den mekaniske natur nedenunder. På trods af disse begrænsninger etablerede disse banebrydende systemer grundlaget, som al fremtidig samtale-AI ville bygge på.
Videnrevolutionen: Ekspertsystemer og struktureret information
1980'erne og begyndelsen af 1990'erne oplevede fremkomsten af ekspertsystemer - AI-programmer designet til at løse komplekse problemer ved at efterligne menneskelige eksperters beslutningsevne inden for specifikke domæner. Selvom de ikke primært er designet til samtale, repræsenterede disse systemer et vigtigt evolutionært skridt for samtale-AI ved at introducere mere sofistikeret videnrepræsentation.
Ekspertsystemer som MYCIN (som diagnosticerede bakterielle infektioner) og DENDRAL (som identificerede kemiske forbindelser) organiserede information i strukturerede vidensbaser og brugte slutningsmotorer til at drage konklusioner. Når den blev anvendt på samtalegrænseflader, tillod denne tilgang chatbots at bevæge sig ud over simpel mønstermatching mod noget, der ligner ræsonnement - i det mindste inden for snævre domæner.
Virksomheder begyndte at implementere praktiske applikationer som automatiserede kundeservicesystemer ved hjælp af denne teknologi. Disse systemer brugte typisk beslutningstræer og menubaserede interaktioner i stedet for frie samtaler, men de repræsenterede tidlige forsøg på at automatisere interaktioner, som tidligere krævede menneskelig indgriben.
Begrænsningerne forblev betydelige. Disse systemer var skøre, ude af stand til at håndtere uventede input på en yndefuld måde. De krævede en enorm indsats fra vidensingeniører for manuelt at indkode information og regler. Og måske vigtigst af alt, kunne de stadig ikke rigtig forstå det naturlige sprog i dets fulde kompleksitet og tvetydighed.
Ikke desto mindre etablerede denne æra vigtige koncepter, som senere ville blive afgørende for moderne samtale-AI: struktureret videnrepræsentation, logisk inferens og domænespecialisering. Scenen var ved at blive sat til et paradigmeskifte, selvom teknologien ikke helt var der endnu.
Ekspertsystemer som MYCIN (som diagnosticerede bakterielle infektioner) og DENDRAL (som identificerede kemiske forbindelser) organiserede information i strukturerede vidensbaser og brugte slutningsmotorer til at drage konklusioner. Når den blev anvendt på samtalegrænseflader, tillod denne tilgang chatbots at bevæge sig ud over simpel mønstermatching mod noget, der ligner ræsonnement - i det mindste inden for snævre domæner.
Virksomheder begyndte at implementere praktiske applikationer som automatiserede kundeservicesystemer ved hjælp af denne teknologi. Disse systemer brugte typisk beslutningstræer og menubaserede interaktioner i stedet for frie samtaler, men de repræsenterede tidlige forsøg på at automatisere interaktioner, som tidligere krævede menneskelig indgriben.
Begrænsningerne forblev betydelige. Disse systemer var skøre, ude af stand til at håndtere uventede input på en yndefuld måde. De krævede en enorm indsats fra vidensingeniører for manuelt at indkode information og regler. Og måske vigtigst af alt, kunne de stadig ikke rigtig forstå det naturlige sprog i dets fulde kompleksitet og tvetydighed.
Ikke desto mindre etablerede denne æra vigtige koncepter, som senere ville blive afgørende for moderne samtale-AI: struktureret videnrepræsentation, logisk inferens og domænespecialisering. Scenen var ved at blive sat til et paradigmeskifte, selvom teknologien ikke helt var der endnu.
Naturlig sprogforståelse: Det computerlingvistiske gennembrud
Slutningen af 1990'erne og begyndelsen af 2000'erne bragte stigende fokus på naturlig sprogbehandling (NLP) og computerlingvistik. I stedet for at prøve at håndkode regler for enhver mulig interaktion, begyndte forskere at udvikle statistiske metoder til at hjælpe computere med at forstå de iboende mønstre i menneskeligt sprog.
Dette skift blev muliggjort af flere faktorer: øget beregningskraft, bedre algoritmer og afgørende, tilgængeligheden af store tekstkorpora, der kunne analyseres for at identificere sproglige mønstre. Systemer begyndte at inkorporere teknikker som:
Orddelingsmærkning: Identifikation af, om ord fungerede som navneord, verber, adjektiver osv.
Genkendelse af navngivne enheder: Registrering og klassificering af egennavne (personer, organisationer, lokationer).
Følelsesanalyse: Bestemmelse af tekstens følelsesmæssige tone.
Parsing: Analyse af sætningsstruktur for at identificere grammatiske sammenhænge mellem ord.
Et bemærkelsesværdigt gennembrud kom med IBMs Watson, som berømt besejrede menneskelige mestre i quizprogrammet Jeopardy! i 2011. Selvom det ikke udelukkende var et samtalesystem, demonstrerede Watson hidtil usete evner til at forstå naturlige sprogspørgsmål, søge gennem enorme videnlagre og formulere svar – egenskaber, der ville vise sig at være afgørende for den næste generation af chatbots.
Kommercielle ansøgninger fulgte snart. Apples Siri blev lanceret i 2011 og bragte samtalegrænseflader til almindelige forbrugere. Selvom det er begrænset af nutidens standarder, repræsenterede Siri et betydeligt fremskridt i at gøre AI-assistenter tilgængelige for hverdagsbrugere. Microsofts Cortana, Googles assistent og Amazons Alexa ville følge efter, som hver især skubbede frem med det nyeste inden for forbrugerrettet konversations-AI.
På trods af disse fremskridt kæmpede systemer fra denne æra stadig med kontekst, sund fornuft ræsonnement og generere virkelig naturligt klingende svar. De var mere sofistikerede end deres regelbaserede forfædre, men forblev fundamentalt begrænsede i deres forståelse af sproget og verden.
Dette skift blev muliggjort af flere faktorer: øget beregningskraft, bedre algoritmer og afgørende, tilgængeligheden af store tekstkorpora, der kunne analyseres for at identificere sproglige mønstre. Systemer begyndte at inkorporere teknikker som:
Orddelingsmærkning: Identifikation af, om ord fungerede som navneord, verber, adjektiver osv.
Genkendelse af navngivne enheder: Registrering og klassificering af egennavne (personer, organisationer, lokationer).
Følelsesanalyse: Bestemmelse af tekstens følelsesmæssige tone.
Parsing: Analyse af sætningsstruktur for at identificere grammatiske sammenhænge mellem ord.
Et bemærkelsesværdigt gennembrud kom med IBMs Watson, som berømt besejrede menneskelige mestre i quizprogrammet Jeopardy! i 2011. Selvom det ikke udelukkende var et samtalesystem, demonstrerede Watson hidtil usete evner til at forstå naturlige sprogspørgsmål, søge gennem enorme videnlagre og formulere svar – egenskaber, der ville vise sig at være afgørende for den næste generation af chatbots.
Kommercielle ansøgninger fulgte snart. Apples Siri blev lanceret i 2011 og bragte samtalegrænseflader til almindelige forbrugere. Selvom det er begrænset af nutidens standarder, repræsenterede Siri et betydeligt fremskridt i at gøre AI-assistenter tilgængelige for hverdagsbrugere. Microsofts Cortana, Googles assistent og Amazons Alexa ville følge efter, som hver især skubbede frem med det nyeste inden for forbrugerrettet konversations-AI.
På trods af disse fremskridt kæmpede systemer fra denne æra stadig med kontekst, sund fornuft ræsonnement og generere virkelig naturligt klingende svar. De var mere sofistikerede end deres regelbaserede forfædre, men forblev fundamentalt begrænsede i deres forståelse af sproget og verden.
Machine Learning og den datadrevne tilgang
Midten af 2010'erne markerede endnu et paradigmeskift i konversations-AI med mainstream-adoptionen af maskinlæringsteknikker. I stedet for at stole på håndlavede regler eller begrænsede statistiske modeller, begyndte ingeniører at bygge systemer, der kunne lære mønstre direkte fra data – og meget af det.
Denne æra oplevede fremkomsten af hensigtsklassificering og enhedsudtrækning som kernekomponenter i samtalearkitektur. Når en bruger fremsatte en anmodning, ville systemet:
Klassificer den overordnede hensigt (f.eks. at booke en flyrejse, tjekke vejret, spille musik)
Udtræk relevante enheder (f.eks. steder, datoer, sangtitler)
Kortlæg disse til specifikke handlinger eller svar
Facebooks (nu Metas) lancering af sin Messenger-platform i 2016 gjorde det muligt for udviklere at skabe chatbots, der kunne nå millioner af brugere, hvilket udløste en bølge af kommerciel interesse. Mange virksomheder skyndte sig at implementere chatbots, selvom resultaterne var blandede. Tidlige kommercielle implementeringer frustrerede ofte brugere med begrænset forståelse og stive samtalestrømme.
Den tekniske arkitektur af samtalesystemer udviklede sig også i denne periode. Den typiske tilgang involverede en pipeline af specialiserede komponenter:
Automatisk talegenkendelse (til stemmegrænseflader)
Naturlig sprogforståelse
Dialogstyring
Naturlig sproggenerering
Tekst-til-tale (til stemmegrænseflader)
Hver komponent kan optimeres separat, hvilket giver mulighed for trinvise forbedringer. Disse pipeline-arkitekturer led dog nogle gange af fejludbredelse - fejl i de tidlige stadier ville kaskade gennem systemet.
Mens maskinlæring forbedrede mulighederne markant, kæmpede systemer stadig med at bevare kontekst over lange samtaler, forstå implicit information og generere virkelig forskelligartede og naturlige svar. Det næste gennembrud ville kræve en mere radikal tilgang.
Denne æra oplevede fremkomsten af hensigtsklassificering og enhedsudtrækning som kernekomponenter i samtalearkitektur. Når en bruger fremsatte en anmodning, ville systemet:
Klassificer den overordnede hensigt (f.eks. at booke en flyrejse, tjekke vejret, spille musik)
Udtræk relevante enheder (f.eks. steder, datoer, sangtitler)
Kortlæg disse til specifikke handlinger eller svar
Facebooks (nu Metas) lancering af sin Messenger-platform i 2016 gjorde det muligt for udviklere at skabe chatbots, der kunne nå millioner af brugere, hvilket udløste en bølge af kommerciel interesse. Mange virksomheder skyndte sig at implementere chatbots, selvom resultaterne var blandede. Tidlige kommercielle implementeringer frustrerede ofte brugere med begrænset forståelse og stive samtalestrømme.
Den tekniske arkitektur af samtalesystemer udviklede sig også i denne periode. Den typiske tilgang involverede en pipeline af specialiserede komponenter:
Automatisk talegenkendelse (til stemmegrænseflader)
Naturlig sprogforståelse
Dialogstyring
Naturlig sproggenerering
Tekst-til-tale (til stemmegrænseflader)
Hver komponent kan optimeres separat, hvilket giver mulighed for trinvise forbedringer. Disse pipeline-arkitekturer led dog nogle gange af fejludbredelse - fejl i de tidlige stadier ville kaskade gennem systemet.
Mens maskinlæring forbedrede mulighederne markant, kæmpede systemer stadig med at bevare kontekst over lange samtaler, forstå implicit information og generere virkelig forskelligartede og naturlige svar. Det næste gennembrud ville kræve en mere radikal tilgang.
Transformer-revolutionen: Neurale sprogmodeller
Året 2017 markerede et skelsættende øjeblik i AI-historien med udgivelsen af "Attention Is All You Need", der introducerede Transformer-arkitekturen, der ville revolutionere naturlig sprogbehandling. I modsætning til tidligere tilgange, der behandlede tekst sekventielt, kunne Transformers overveje en hel passage samtidigt, hvilket giver dem mulighed for bedre at fange relationer mellem ord uanset deres afstand fra hinanden.
Denne innovation muliggjorde udviklingen af stadig stærkere sprogmodeller. I 2018 introducerede Google BERT (Bidirectional Encoder Representations from Transformers), som dramatisk forbedrede ydeevnen på forskellige sprogforståelsesopgaver. I 2019 udgav OpenAI GPT-2, der demonstrerede hidtil usete evner til at generere sammenhængende, kontekstuelt relevant tekst.
Det mest dramatiske spring kom i 2020 med GPT-3, der skaleres op til 175 milliarder parametre (sammenlignet med GPT-2's 1,5 milliarder). Denne massive stigning i skala, kombineret med arkitektoniske raffinementer, producerede kvalitativt forskellige muligheder. GPT-3 kunne generere bemærkelsesværdigt menneskelignende tekst, forstå kontekst på tværs af tusindvis af ord og endda udføre opgaver, den ikke eksplicit var trænet i.
For konversations-AI blev disse fremskridt oversat til chatbots, der kunne:
Oprethold sammenhængende samtaler over mange omgange
Forstå nuancerede forespørgsler uden eksplicit træning
Generer forskellige, kontekstuelt passende svar
Tilpas deres tone og stil til at matche brugeren
Håndter uklarhed og afklar, når det er nødvendigt
Udgivelsen af ChatGPT i slutningen af 2022 bragte disse funktioner til mainstream og tiltrak over en million brugere inden for få dage efter lanceringen. Pludselig havde den brede offentlighed adgang til konversations-AI, der virkede kvalitativt anderledes end noget, der kom før – mere fleksibel, mere vidende og mere naturlig i dens interaktioner.
Kommercielle implementeringer fulgte hurtigt, hvor virksomheder inkorporerede store sprogmodeller i deres kundeserviceplatforme, værktøjer til oprettelse af indhold og produktivitetsapplikationer. Den hurtige adoption afspejlede både det teknologiske spring og den intuitive grænseflade, disse modeller gav – samtale er trods alt den mest naturlige måde for mennesker at kommunikere på.
Denne innovation muliggjorde udviklingen af stadig stærkere sprogmodeller. I 2018 introducerede Google BERT (Bidirectional Encoder Representations from Transformers), som dramatisk forbedrede ydeevnen på forskellige sprogforståelsesopgaver. I 2019 udgav OpenAI GPT-2, der demonstrerede hidtil usete evner til at generere sammenhængende, kontekstuelt relevant tekst.
Det mest dramatiske spring kom i 2020 med GPT-3, der skaleres op til 175 milliarder parametre (sammenlignet med GPT-2's 1,5 milliarder). Denne massive stigning i skala, kombineret med arkitektoniske raffinementer, producerede kvalitativt forskellige muligheder. GPT-3 kunne generere bemærkelsesværdigt menneskelignende tekst, forstå kontekst på tværs af tusindvis af ord og endda udføre opgaver, den ikke eksplicit var trænet i.
For konversations-AI blev disse fremskridt oversat til chatbots, der kunne:
Oprethold sammenhængende samtaler over mange omgange
Forstå nuancerede forespørgsler uden eksplicit træning
Generer forskellige, kontekstuelt passende svar
Tilpas deres tone og stil til at matche brugeren
Håndter uklarhed og afklar, når det er nødvendigt
Udgivelsen af ChatGPT i slutningen af 2022 bragte disse funktioner til mainstream og tiltrak over en million brugere inden for få dage efter lanceringen. Pludselig havde den brede offentlighed adgang til konversations-AI, der virkede kvalitativt anderledes end noget, der kom før – mere fleksibel, mere vidende og mere naturlig i dens interaktioner.
Kommercielle implementeringer fulgte hurtigt, hvor virksomheder inkorporerede store sprogmodeller i deres kundeserviceplatforme, værktøjer til oprettelse af indhold og produktivitetsapplikationer. Den hurtige adoption afspejlede både det teknologiske spring og den intuitive grænseflade, disse modeller gav – samtale er trods alt den mest naturlige måde for mennesker at kommunikere på.
Test AI på DIN hjemmeside på 60 sekunder
Se hvordan vores AI øjeblikkeligt analyserer din hjemmeside og skaber en personlig chatbot - uden registrering. Indtast blot din URL og se den arbejde!
Klar på 60 sekunder
Ingen kodning påkrævet
100% sikker
Multimodale muligheder: Ud over tekst-kun samtaler
Mens tekst har domineret konversations-AI-udvikling, har de seneste år set et skub i retning af multimodale systemer, der kan forstå og generere flere typer medier. Denne udvikling afspejler en grundlæggende sandhed om menneskelig kommunikation – vi bruger ikke kun ord; vi gestikulerer, viser billeder, tegner diagrammer og bruger vores miljø til at formidle mening.
Visionssprogede modeller som DALL-E, Midjourney og Stable Diffusion demonstrerede evnen til at generere billeder ud fra tekstbeskrivelser, mens modeller som GPT-4 med synsevner kunne analysere billeder og diskutere dem intelligent. Dette åbnede nye muligheder for samtalegrænseflader:
Kundeservice-bots, der kan analysere billeder af beskadigede produkter
Indkøbsassistenter, der kan identificere varer fra billeder og finde lignende produkter
Pædagogiske værktøjer, der kan forklare diagrammer og visuelle begreber
Tilgængelighedsfunktioner, der kan beskrive billeder for synshandicappede brugere
Stemmefunktionerne er også udviklet dramatisk. Tidlige talegrænseflader som IVR-systemer (Interactive Voice Response) var notorisk frustrerende, begrænset til stive kommandoer og menustrukturer. Moderne stemmeassistenter kan forstå naturlige talemønstre, tage højde for forskellige accenter og talehæmninger og reagere med syntetiserede stemmer, der i stigende grad lyder naturligt.
Sammensmeltningen af disse muligheder skaber ægte multimodal konversations-AI, der problemfrit kan skifte mellem forskellige kommunikationstilstande baseret på kontekst og brugerbehov. En bruger kan starte med et tekstspørgsmål om at reparere deres printer, sende et billede af fejlmeddelelsen, modtage et diagram, der fremhæver relevante knapper, og derefter skifte til stemmeinstruktioner, mens deres hænder er i gang med reparationen.
Denne multimodale tilgang repræsenterer ikke kun et teknisk fremskridt, men et fundamentalt skift i retning af mere naturlig menneske-computer-interaktion – at møde brugere i den kommunikationstilstand, der fungerer bedst til deres nuværende kontekst og behov.
Visionssprogede modeller som DALL-E, Midjourney og Stable Diffusion demonstrerede evnen til at generere billeder ud fra tekstbeskrivelser, mens modeller som GPT-4 med synsevner kunne analysere billeder og diskutere dem intelligent. Dette åbnede nye muligheder for samtalegrænseflader:
Kundeservice-bots, der kan analysere billeder af beskadigede produkter
Indkøbsassistenter, der kan identificere varer fra billeder og finde lignende produkter
Pædagogiske værktøjer, der kan forklare diagrammer og visuelle begreber
Tilgængelighedsfunktioner, der kan beskrive billeder for synshandicappede brugere
Stemmefunktionerne er også udviklet dramatisk. Tidlige talegrænseflader som IVR-systemer (Interactive Voice Response) var notorisk frustrerende, begrænset til stive kommandoer og menustrukturer. Moderne stemmeassistenter kan forstå naturlige talemønstre, tage højde for forskellige accenter og talehæmninger og reagere med syntetiserede stemmer, der i stigende grad lyder naturligt.
Sammensmeltningen af disse muligheder skaber ægte multimodal konversations-AI, der problemfrit kan skifte mellem forskellige kommunikationstilstande baseret på kontekst og brugerbehov. En bruger kan starte med et tekstspørgsmål om at reparere deres printer, sende et billede af fejlmeddelelsen, modtage et diagram, der fremhæver relevante knapper, og derefter skifte til stemmeinstruktioner, mens deres hænder er i gang med reparationen.
Denne multimodale tilgang repræsenterer ikke kun et teknisk fremskridt, men et fundamentalt skift i retning af mere naturlig menneske-computer-interaktion – at møde brugere i den kommunikationstilstand, der fungerer bedst til deres nuværende kontekst og behov.
Retrieval-Augmented Generation: Grounding AI i fakta
På trods af deres imponerende egenskaber har store sprogmodeller iboende begrænsninger. De kan "hallucinere" information og med sikkerhed angive plausible, men ukorrekte fakta. Deres viden er begrænset til, hvad der var i deres træningsdata, hvilket skaber en skæringsdato for viden. Og de mangler muligheden for at få adgang til information i realtid eller specialiserede databaser, medmindre de er specielt udviklet til at gøre det.
Retrieval-Augmented Generation (RAG) opstod som en løsning på disse udfordringer. I stedet for udelukkende at stole på parametre lært under træning, kombinerer RAG-systemer de generative evner i sprogmodeller med genfindingsmekanismer, der kan få adgang til eksterne videnkilder.
Den typiske RAG-arkitektur fungerer således:
Systemet modtager en brugerforespørgsel
Den søger i relevante vidensbaser efter oplysninger, der er relevante for forespørgslen
Det fører både forespørgslen og den hentede information til sprogmodellen
Modellen genererer en respons baseret på de hentede fakta
Denne tilgang giver flere fordele:
Mere nøjagtige, faktuelle svar ved at basere generering i verificerede oplysninger
Muligheden for at få adgang til opdateret information ud over modellens træningsgrænse
Specialiseret viden fra domænespecifikke kilder som virksomhedsdokumentation
Gennemsigtighed og attribution ved at citere informationskilderne
For virksomheder, der implementerer konversations-AI, har RAG vist sig særligt værdifuldt til kundeserviceapplikationer. En bankchatbot kan for eksempel få adgang til de seneste politiske dokumenter, kontooplysninger og transaktionsregistreringer for at give nøjagtige, personlige svar, som ville være umulige med en selvstændig sprogmodel.
Udviklingen af RAG-systemer fortsætter med forbedringer i genfindingsnøjagtighed, mere sofistikerede metoder til at integrere hentet information med genereret tekst og bedre mekanismer til at evaluere pålideligheden af forskellige informationskilder.
Retrieval-Augmented Generation (RAG) opstod som en løsning på disse udfordringer. I stedet for udelukkende at stole på parametre lært under træning, kombinerer RAG-systemer de generative evner i sprogmodeller med genfindingsmekanismer, der kan få adgang til eksterne videnkilder.
Den typiske RAG-arkitektur fungerer således:
Systemet modtager en brugerforespørgsel
Den søger i relevante vidensbaser efter oplysninger, der er relevante for forespørgslen
Det fører både forespørgslen og den hentede information til sprogmodellen
Modellen genererer en respons baseret på de hentede fakta
Denne tilgang giver flere fordele:
Mere nøjagtige, faktuelle svar ved at basere generering i verificerede oplysninger
Muligheden for at få adgang til opdateret information ud over modellens træningsgrænse
Specialiseret viden fra domænespecifikke kilder som virksomhedsdokumentation
Gennemsigtighed og attribution ved at citere informationskilderne
For virksomheder, der implementerer konversations-AI, har RAG vist sig særligt værdifuldt til kundeserviceapplikationer. En bankchatbot kan for eksempel få adgang til de seneste politiske dokumenter, kontooplysninger og transaktionsregistreringer for at give nøjagtige, personlige svar, som ville være umulige med en selvstændig sprogmodel.
Udviklingen af RAG-systemer fortsætter med forbedringer i genfindingsnøjagtighed, mere sofistikerede metoder til at integrere hentet information med genereret tekst og bedre mekanismer til at evaluere pålideligheden af forskellige informationskilder.
Human-AI-samarbejdsmodellen: At finde den rigtige balance
Efterhånden som samtale-AI-kapaciteter er blevet udvidet, har forholdet mellem mennesker og AI-systemer udviklet sig. Tidlige chatbots var tydeligt placeret som værktøjer – begrænset i omfang og åbenlyst ikke-menneskelige i deres interaktioner. Moderne systemer slører disse linjer og skaber nye spørgsmål om, hvordan man designer effektivt menneske-AI-samarbejde.
De mest succesrige implementeringer i dag følger en samarbejdsmodel, hvor:
AI'en håndterer rutinemæssige, gentagne forespørgsler, der ikke kræver menneskelig dømmekraft
Mennesker fokuserer på komplekse sager, der kræver empati, etisk ræsonnement eller kreativ problemløsning
Systemet kender sine begrænsninger og eskalerer jævnt til menneskelige agenter, når det er relevant
Overgangen mellem kunstig intelligens og menneskelig støtte er problemfri for brugeren
Menneskelige agenter har fuld kontekst af samtalehistorien med AI
AI fortsætter med at lære af menneskelige indgreb og udvider gradvist sine muligheder
Denne tilgang anerkender, at konversations-AI ikke bør sigte mod fuldstændig at erstatte menneskelig interaktion, men snarere at komplementere den – håndtering af de store, ligefremme forespørgsler, der optager menneskelige agenters tid og samtidig sikre, at komplekse problemer når den rette menneskelige ekspertise.
Implementeringen af denne model varierer på tværs af brancher. I sundhedssektoren kan AI-chatbots håndtere aftaleplanlægning og grundlæggende symptomscreening, mens de sikrer, at lægelig rådgivning kommer fra kvalificerede fagfolk. Inden for juridiske tjenester kan kunstig intelligens måske hjælpe med dokumentforberedelse og forskning, mens fortolkning og strategi overlades til advokater. I kundeservice kan AI løse almindelige problemer, mens komplekse problemer dirigeres til specialiserede agenter.
Efterhånden som AI-kapaciteter fortsætter med at udvikle sig, vil grænsen mellem, hvad der kræver menneskelig involvering, og hvad der kan automatiseres, skifte, men det grundlæggende princip forbliver: effektiv samtale-AI bør forbedre menneskelige evner i stedet for blot at erstatte dem.
De mest succesrige implementeringer i dag følger en samarbejdsmodel, hvor:
AI'en håndterer rutinemæssige, gentagne forespørgsler, der ikke kræver menneskelig dømmekraft
Mennesker fokuserer på komplekse sager, der kræver empati, etisk ræsonnement eller kreativ problemløsning
Systemet kender sine begrænsninger og eskalerer jævnt til menneskelige agenter, når det er relevant
Overgangen mellem kunstig intelligens og menneskelig støtte er problemfri for brugeren
Menneskelige agenter har fuld kontekst af samtalehistorien med AI
AI fortsætter med at lære af menneskelige indgreb og udvider gradvist sine muligheder
Denne tilgang anerkender, at konversations-AI ikke bør sigte mod fuldstændig at erstatte menneskelig interaktion, men snarere at komplementere den – håndtering af de store, ligefremme forespørgsler, der optager menneskelige agenters tid og samtidig sikre, at komplekse problemer når den rette menneskelige ekspertise.
Implementeringen af denne model varierer på tværs af brancher. I sundhedssektoren kan AI-chatbots håndtere aftaleplanlægning og grundlæggende symptomscreening, mens de sikrer, at lægelig rådgivning kommer fra kvalificerede fagfolk. Inden for juridiske tjenester kan kunstig intelligens måske hjælpe med dokumentforberedelse og forskning, mens fortolkning og strategi overlades til advokater. I kundeservice kan AI løse almindelige problemer, mens komplekse problemer dirigeres til specialiserede agenter.
Efterhånden som AI-kapaciteter fortsætter med at udvikle sig, vil grænsen mellem, hvad der kræver menneskelig involvering, og hvad der kan automatiseres, skifte, men det grundlæggende princip forbliver: effektiv samtale-AI bør forbedre menneskelige evner i stedet for blot at erstatte dem.
Fremtidens landskab: Hvor Conversational AI er på vej
Når vi ser ud i horisonten, former flere nye tendenser fremtiden for konversations-AI. Disse udviklinger lover ikke kun trinvise forbedringer, men potentielt transformative ændringer i, hvordan vi interagerer med teknologi.
Personalisering i stor skala: Fremtidige systemer vil i stigende grad skræddersy deres svar ikke kun til den umiddelbare kontekst, men til hver brugers kommunikationsstil, præferencer, vidensniveau og relationshistorie. Denne personalisering vil få interaktioner til at føles mere naturlige og relevante, selvom den rejser vigtige spørgsmål om privatliv og databrug.
Følelsesmæssig intelligens: Mens nutidens systemer kan registrere grundlæggende følelser, vil fremtidig samtale-AI udvikle mere sofistikeret følelsesmæssig intelligens – genkende subtile følelsesmæssige tilstande, reagere passende på nød eller frustration og tilpasse dens tone og tilgang i overensstemmelse hermed. Denne evne vil være særlig værdifuld i kundeservice, sundhedspleje og uddannelsesapplikationer.
Proaktiv assistance: I stedet for at vente på eksplicitte forespørgsler, vil næste generations samtalesystemer forudse behov baseret på kontekst, brugerhistorie og miljøsignaler. Et system kan bemærke, at du planlægger flere møder i en ukendt by og proaktivt tilbyder transportmuligheder eller vejrudsigter.
Sømløs multimodal integration: Fremtidige systemer vil bevæge sig ud over blot at understøtte forskellige modaliteter til sømløst at integrere dem. En samtale kan flyde naturligt mellem tekst, stemme, billeder og interaktive elementer ved at vælge den rigtige modalitet for hver enkelt information uden at kræve eksplicit brugervalg.
Specialiserede domæneeksperter: Mens assistenter til generelle formål vil fortsætte med at forbedre sig, vil vi også se fremkomsten af højt specialiseret samtale-AI med dyb ekspertise inden for specifikke domæner – juridiske assistenter, der forstår retspraksis og præcedens, medicinske systemer med omfattende viden om lægemiddelinteraktioner og behandlingsprotokoller, eller finansielle rådgivere, der er fortrolige med skatteregler og investeringsstrategier.
Virkelig kontinuerlig læring: Fremtidige systemer vil bevæge sig ud over periodisk omskoling til kontinuerlig læring fra interaktioner, blive mere hjælpsomme og personaliserede over tid, samtidig med at de bevarer passende beskyttelse af privatlivets fred.
På trods af disse spændende muligheder er der stadig udfordringer. Bekymringer om beskyttelse af privatlivets fred, begrænsning af partiskhed, passende gennemsigtighed og etablering af det rette niveau af menneskeligt tilsyn er igangværende spørgsmål, som vil forme både teknologien og dens regulering. De mest succesfulde implementeringer vil være dem, der løser disse udfordringer omhyggeligt, mens de leverer ægte værdi til brugerne.
Det, der er klart, er, at konversations-AI har bevæget sig fra en nicheteknologi til et almindeligt grænsefladeparadigme, der i stigende grad vil formidle vores interaktioner med digitale systemer. Den evolutionære vej fra ELIZAs enkle mønstermatchning til nutidens sofistikerede sprogmodeller repræsenterer et af de mest betydningsfulde fremskridt inden for menneske-computer-interaktion – og rejsen er langt fra slut.
Personalisering i stor skala: Fremtidige systemer vil i stigende grad skræddersy deres svar ikke kun til den umiddelbare kontekst, men til hver brugers kommunikationsstil, præferencer, vidensniveau og relationshistorie. Denne personalisering vil få interaktioner til at føles mere naturlige og relevante, selvom den rejser vigtige spørgsmål om privatliv og databrug.
Følelsesmæssig intelligens: Mens nutidens systemer kan registrere grundlæggende følelser, vil fremtidig samtale-AI udvikle mere sofistikeret følelsesmæssig intelligens – genkende subtile følelsesmæssige tilstande, reagere passende på nød eller frustration og tilpasse dens tone og tilgang i overensstemmelse hermed. Denne evne vil være særlig værdifuld i kundeservice, sundhedspleje og uddannelsesapplikationer.
Proaktiv assistance: I stedet for at vente på eksplicitte forespørgsler, vil næste generations samtalesystemer forudse behov baseret på kontekst, brugerhistorie og miljøsignaler. Et system kan bemærke, at du planlægger flere møder i en ukendt by og proaktivt tilbyder transportmuligheder eller vejrudsigter.
Sømløs multimodal integration: Fremtidige systemer vil bevæge sig ud over blot at understøtte forskellige modaliteter til sømløst at integrere dem. En samtale kan flyde naturligt mellem tekst, stemme, billeder og interaktive elementer ved at vælge den rigtige modalitet for hver enkelt information uden at kræve eksplicit brugervalg.
Specialiserede domæneeksperter: Mens assistenter til generelle formål vil fortsætte med at forbedre sig, vil vi også se fremkomsten af højt specialiseret samtale-AI med dyb ekspertise inden for specifikke domæner – juridiske assistenter, der forstår retspraksis og præcedens, medicinske systemer med omfattende viden om lægemiddelinteraktioner og behandlingsprotokoller, eller finansielle rådgivere, der er fortrolige med skatteregler og investeringsstrategier.
Virkelig kontinuerlig læring: Fremtidige systemer vil bevæge sig ud over periodisk omskoling til kontinuerlig læring fra interaktioner, blive mere hjælpsomme og personaliserede over tid, samtidig med at de bevarer passende beskyttelse af privatlivets fred.
På trods af disse spændende muligheder er der stadig udfordringer. Bekymringer om beskyttelse af privatlivets fred, begrænsning af partiskhed, passende gennemsigtighed og etablering af det rette niveau af menneskeligt tilsyn er igangværende spørgsmål, som vil forme både teknologien og dens regulering. De mest succesfulde implementeringer vil være dem, der løser disse udfordringer omhyggeligt, mens de leverer ægte værdi til brugerne.
Det, der er klart, er, at konversations-AI har bevæget sig fra en nicheteknologi til et almindeligt grænsefladeparadigme, der i stigende grad vil formidle vores interaktioner med digitale systemer. Den evolutionære vej fra ELIZAs enkle mønstermatchning til nutidens sofistikerede sprogmodeller repræsenterer et af de mest betydningsfulde fremskridt inden for menneske-computer-interaktion – og rejsen er langt fra slut.





